
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- GPT 멀티챗
- envoy
- Ingress
- aws eks
- argocd
- K8S
- Streamlit 활용한 챗봇만들기
- PuMuPDF
- Kind
- Jenkins
- 멀티에이전트 RAG
- kiali
- Ambient
- Kubernetes
- 랭그래프 목차만들기
- service mesh
- docker
- vpc cni
- 타빌리
- GPT 역할 부여하기
- Istio
- loadbalancer
- WSL
- CNI
- prometheus
- 스트림릿 활용한 GPT
- CICD
- vagrant
- Observability
- grafana
- Today
- Total
WellSpring
AEWS 9주차 - EKS Upgrade [AWS Workshop] 본문
목차
※ 본 게재 글은 gasida님의 'AEWS' 강의내용과 실습예제 및 AWS 공식 workshop 환경을 기반으로 작성하였습니다.
1. K8S 업그레이드
▶ [K8S Docs] Release* : 1년에 3개의 마이너 버전 출시 → 최근 3개 버전 release branches(패치) 지원 - Link
1. Kubernetes 의 릴리즈는 1년에 3개의 마이너 버전을 기본으로 한다.

2. 버전 정보는 Semantic Versioning 방식을 이용한다. - Link
Given a version number MAJOR.MINOR.PATCH, increment the:
- MAJOR version when you make incompatible API changes
- MINOR version when you add functionality in a backward compatible manner
- PATCH version when you make backward compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
[ 기본 규칙 ]
- MAJOR version 이 올라가면, MINOR Version 과 Patch Version 은 0 이 되어야 한다.
- MINOR Version 이 올라가면, Patch Version은 0 이 되어야 한다.
- 정식 배포 전에 pre-release 하는 경우 '-' 또는 '.' 을 사용한다.
- 정식 배포 전 git commit 후, 난수가 붙은 형태 그대로 배포하는 것을 Build metadata 라고 부른다.
- MAJOR 에 0 으로 시작하는 경우 (0.y.z)는 초기 개발 버전을 나타내기 위해 사용한다.
3. Patch 관리 - Link
- Upcoming Release 정보를 참고하자!!
- Download - Link
- Release Cycle - Link
- Patch Releases - Link
- Release Managers - Link
- Release Notes - Link
4. Version Skew Policy* - Link
- kube-apiserver : HA apiserver 경우 newest 와 oldest 가 1개 마이너 버전 가능
- newest kube-apiserver is at 1.32
- other kube-apiserver instances are supported at 1.32 and 1.31
- kubelet/kube-proxy : kubelet 는 apiserver 보다 높을수 없음. 추가로 apiserver 보다 3개 older 가능
- kube-apiserver is at 1.32
- kubelet is supported at 1.32, 1.31, 1.30, and 1.29
- 만약 apiserver 가 HA로 1.32, 1.31 있다면 kubelet 는 1.32는 안되고, 1.31, 1.30, 1.29 가능
- kube-controller-manager, kube-scheduler, and cloud-controller-manager : skip
- kubectl : one minor version (older or newer) of kube-apiserver
- kube-apiserver is at 1.32
- kubectl is supported at 1.33, 1.32, and 1.31
2. 가상 온프레미스 환경 K8S에서 업그레이드 계획 짜기
▶ 환경 소개 : k8s 1.28, CPx3대, DPx3대, HW LB 사용 중
[ 구성도 ]

- 구성 요소 및 버전
0. 목표 버전 설정 : K8S 1.32!
1. 버전 호환성 검토
- K8S(kubelet, apiserver..) 1.32 요구 커널 버전 확인 : 예) user namespace 사용 시 커널 6.5 이상 필요 - Docs
- containerd 버전 조사 : 예) user namespace 에 대한 CRI 지원 시 containerd v2.0 및 runc v1.2 이상 필요 - Docs
- K8S 호환 버전 확인 - Docs
- CNI(Cilium) 요구 커널 버전 확인 : 예) BPF-based host routing 기능 필요 시 커널 5.10 이상 필요 - Docs
- CNI 이 지원하는 K8S 버전 확인 - Docs
- CSI : Skip…
- 애플리케이션 요구사항 검토
2. 업그레이드 방법 결정 : in-place vs blue-green
3. 결정된 방법으로 업그레이드 계획 수립
☞ In-place 결정 시,

4. 사전 준비
- (옵션) 각 작업 별 상세 명령 실행 및 스크립트 작성, 작업 중단 실패 시 롤백 명령/스크립트 작성
- 모니터링 설정
- (1) ETCD 백업
- (2) CNI(cilium) 업그레이드
5. CP 노드 순차 업그레이드 : 1.28 → 1.29 → 1.30
- 노드 1대씩 작업 진행 1.28 → 1.29
- (3) Ubuntu OS(kernel) 업그레이드 → 재부팅
- (4) containerd 업그레이드 → containerd 서비스 재시작
- (5) kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 노드 1대씩 작업 진행 1.29 → 1.30
- (5) kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 CP 노드 상태 확인
6. DP 노드 순차 업그레이드 : 1.28 → 1.29 → 1.30
- 노드 1대씩 작업 진행 1.28 → 1.29
- (6) 작업 노드 drain 설정 후 파드 Evicted 확인, 서비스 중단 여부 모니터링 확인
- (7) Ubuntu OS(kernel) 업그레이드 → 재부팅
- (8) containerd 업그레이드 → containerd 서비스 재시작
- (9) kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 노드 1대씩 작업 진행 1.29 → 1.30
- (9) kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 DP 노드 상태 확인 ⇒ (10) 작업 노드 uncordon 설정 후 다시 상태 확인
7. K8S 관련 전체적인 동작 1차 점검
- 애플리케이션 파드 동작 확인 등
8. CP 노드 순차 업그레이드 : 1.30 → 1.31 → 1.32
- 노드 1대씩 작업 진행 x 버전별 반복
- kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 CP 노드 상태 확인
9. DP 노드 순차 업그레이드 : 1.30 → 1.31 → 1.32
- 노드 1대씩 작업 진행 x 버전별 반복
- 작업 노드 drain 설정 후 파드 Evicted 확인, 서비스 중단 여부 모니터링 확인
- kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 DP 노드 상태 확인 ⇒ 작업 노드 uncordon 설정 후 다시 상태 확인
10. K8S 관련 전체적인 동작 2차 점검
- 애플리케이션 파드 동작 확인 등
3. Amazon EKS Upgrades: Strategies and Best Practices
☞ Amazon EKS 클러스터 업그레이드 워크숍의 목적은 고객에게 Amazon EKS 클러스터 업그레이드를 계획하고 실행할 수 있는 모범 사례를 제공하는 일련의 실험실을 소개하는 것입니다.
우리는 In-Place, Blue/Green 등 다양한 클러스터 업그레이드 전략을 탐구하고 각 전략의 실행 세부 사항을 자세히 살펴볼 것입니다.
이 워크숍에서는 EKS 테라폼 청사진, ArgoCD 등을 활용하여 전체 EKS 클러스터 업그레이드 프로세스를 안내합니다.
3-1. Getting Start
Step1. IDE 서버 환경 접속 - 오레곤 리전(us-west-2)
- 주어진 URL과 Password 를 통해 Terraform 코드 수정할 수 있는 환경 포함된 IDE 서버에 접속
Step2. IDE 정보 확인 : 버전(1.25.16), 노드(AL2, 커널 5.10.234, containerd 1.7.25) - IDE_Link , Self-Mng-Node , KrBlog
1) 기본 정보 확인
#
whoami
ec2-user
pwd
/home/ec2-user/environment
export
declare -x ASSETS_BUCKET="ws-event-069b6df5-757-us-west-2/d2117abb-06fa-4e89-8a6b-8e2b5d6fc697/assets/"
declare -x AWS_DEFAULT_REGION="us-west-2"
declare -x AWS_PAGER=""
declare -x AWS_REGION="us-west-2"
declare -x CLUSTER_NAME="eksworkshop-eksctl"
declare -x EC2_PRIVATE_IP="192.168.0.59"
declare -x EKS_CLUSTER_NAME="eksworkshop-eksctl"
declare -x GIT_ASKPASS="/usr/lib/code-server/lib/vscode/extensions/git/dist/askpass.sh"
declare -x HOME="/home/ec2-user"
declare -x HOSTNAME="ip-192-168-0-59.us-west-2.compute.internal"
declare -x IDE_DOMAIN="dboqritcd2u5f.cloudfront.net"
declare -x IDE_PASSWORD="pKsnXRPkxDvZH2GfZ9IPF3ULW74RbKjH"
declare -x IDE_URL="https://dboqritcd2u5f.cloudfront.net"
declare -x INSTANCE_IAM_ROLE_ARN="arn:aws:iam::271345173787:role/workshop-stack-IdeIdeRoleD654ADD4-Qhv1nLkOGItJ"
declare -x INSTANCE_IAM_ROLE_NAME="workshop-stack-IdeIdeRoleD654ADD4-Qhv1nLkOGItJ"
declare -x REGION="us-west-2"
declare -x TF_STATE_S3_BUCKET="workshop-stack-tfstatebackendbucketf0fc9a9d-isuyoohioh8p"
declare -x TF_VAR_aws_region="us-west-2"
declare -x TF_VAR_eks_cluster_id="eksworkshop-eksctl"
declare -x USER="ec2-user"
declare -x VSCODE_PROXY_URI="https://dboqritcd2u5f.cloudfront.net/proxy/{{port}}/"
...
# s3 버킷 확인
aws s3 ls
2025-03-28 11:56:25 workshop-stack-tfstatebackendbucketf0fc9a9d-2phddn8usnlw
aws s3 ls s3://workshop-stack-tfstatebackendbucketf0fc9a9d-2phddn8usnlw
2025-03-28 12:18:23 940996 terraform.tfstate
# 환경변수(테라폼 포함) 및 단축키 alias 등 확인
cat ~/.bashrc
...
export EKS_CLUSTER_NAME=eksworkshop-eksctl
export CLUSTER_NAME=eksworkshop-eksctl
export AWS_DEFAULT_REGION=us-west-2
export REGION=us-west-2
export AWS_REGION=us-west-2
export TF_VAR_eks_cluster_id=eksworkshop-eksctl
export TF_VAR_aws_region=us-west-2
export ASSETS_BUCKET=ws-event-069b6df5-757-us-west-2/d2117abb-06fa-4e89-8a6b-8e2b5d6fc697/assets/
export TF_STATE_S3_BUCKET=workshop-stack-tfstatebackendbucketf0fc9a9d-isuyoohioh8p
alias k=kubectl
alias kgn="kubectl get nodes -o wide"
alias kgs="kubectl get svc -o wide"
alias kgd="kubectl get deploy -o wide"
alias kgsa="kubectl get svc -A -o wide"
alias kgda="kubectl get deploy -A -o wide"
alias kgp="kubectl get pods -o wide"
alias kgpa="kubectl get pods -A -o wide"
aws eks update-kubeconfig --name eksworkshop-eksctl
export AWS_PAGER=""
# eks 플랫폼 버전 eks.44
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq
{
"cluster": {
"name": "eksworkshop-eksctl",
"arn": "arn:aws:eks:us-west-2:271345173787:cluster/eksworkshop-eksctl",
"createdAt": "2025-03-25T02:20:34.060000+00:00",
"version": "1.25",
"endpoint": "https://B852364D70EA6D62672481D278A15059.gr7.us-west-2.eks.amazonaws.com",
"roleArn": "arn:aws:iam::271345173787:role/eksworkshop-eksctl-cluster-20250325022010584300000004",
"resourcesVpcConfig": {
"subnetIds": [
"subnet-047ab61ad85c50486",
"subnet-0aeb12f673d69f7c5",
"subnet-01bbd11a892aec6ee"
],
"securityGroupIds": [
"sg-0ef166af090e168d5"
],
"clusterSecurityGroupId": "sg-09f8b41af6cadd619",
"vpcId": "vpc-052bf403eaa32d5de",
"endpointPublicAccess": true,
"endpointPrivateAccess": true,
"publicAccessCidrs": [
"0.0.0.0/0"
]
},
"kubernetesNetworkConfig": {
"serviceIpv4Cidr": "172.20.0.0/16",
"ipFamily": "ipv4",
"elasticLoadBalancing": {
"enabled": false
}
},
"logging": {
"clusterLogging": [
{
"types": [
"api",
"audit",
"authenticator"
],
"enabled": true
},
{
"types": [
"controllerManager",
"scheduler"
],
"enabled": false
}
]
},
"identity": {
"oidc": {
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059"
}
},
"status": "ACTIVE",
"certificateAuthority": {
"data": "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURCVENDQWUyZ0F3SUJBZ0lJUG52UE1YVThibmd3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TlRBek1qVXdNakl3TkRSYUZ3MHpOVEF6TWpNd01qSTFORFJhTUJVeApFekFSQmdOVkJBTVRDbXQxWW1WeWJtVjBaWE13Z2dFaU1BMEdDU3FHU0liM0RRRUJBUVVBQTRJQkR3QXdnZ0VLCkFvSUJBUURDMGxZNk9kTkhqQlhyaStPVUd0cHQ1UVl3YUdCZUw5V2s1QkFwSUQrRVllQVQzS1k5VmFQSGhUK2cKdTIyM096SHlXUjNJNjlhbWd2cS94RUg2RUFqRUFUTkxKWHd3MXQ1dVNhaG1Ia3lUWEhtUkl2M3hwQVEzalY0KwpReFQrWWJBYjNpMjdjd3d5OGNRckRBTU1BZUszd29JWmR5OVkxWUx2ZkMxUnA4WEU3bitLcGpRTkE5UmlvYzFxCnU2RGh0bzJ5dHdOTE5WQ0RuRSswbTN2M3AzMlZFTW91UjlMbkFRaEUza1BvL2ZjeVB6VWVQelMwRTdRdTdXSmMKZXJHcGNBbmtFdithRjNiK2p5ZndiWHBFLzFCQWtaZWt2UmtsN0FreVF2ZU5wU1RITEZnZDNMamtnWE52djFEcwp5SUI1UHJKSGV6RTk2UEZFbkRGMGtmZGVaVzNGQWdNQkFBR2pXVEJYTUE0R0ExVWREd0VCL3dRRUF3SUNwREFQCkJnTlZIUk1CQWY4RUJUQURBUUgvTUIwR0ExVWREZ1FXQkJSVm9zWGs2Zyt4ek9ycEd6QTlOU0xnTmVSalhUQVYKQmdOVkhSRUVEakFNZ2dwcmRXSmxjbTVsZEdWek1BMEdDU3FHU0liM0RRRUJDd1VBQTRJQkFRQy9qQWtUMHJRcwpyaDFrZ2ozOG54b3c2WkdsVUxCKzQrY0NPU3p1K3FpNDFTWVpHamliemJXTklBTGIzakFCNEd4Y05sbWxlTVE2Cms5V0JqZk1yb3d6ZHhNQWZOc2R6VStUMGx1dmhSUkVRZjVDL0pNaVdtVWRuZGo1SHhWQmFLM0luc0pUV2hCRlIKSFdEaEcwVm5qeGJiVitlQnZYQUtaWmNuc21iMm5JNENxWGRBdWxKbFFiY201Y25UTDNBOXlYdzY5K1ZucCtmdgo3czFRd3pnWCt0NFc3Zm1DeEVCN1hoL2MyaXg3Q1hER0hqWE1OWVFsNVlNbEdWaWVWbTFKQkhWaUhXYlA4UE9JCmpEbUcvWDExZVczRFhoQ24yTFU1dlVOQTZKNUFQTmlBb0J5WU54VGhndDkvem5zZG0xL1dNZDQ5U0RGREVUcWkKeGhRWjlqQ2VNbXZFCi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K"
},
"platformVersion": "eks.44",
"tags": {
"karpenter.sh/discovery": "eksworkshop-eksctl",
"terraform-aws-modules": "eks",
"Blueprint": "eksworkshop-eksctl",
"GithubRepo": "github.com/aws-ia/terraform-aws-eks-blueprints"
},
"encryptionConfig": [
{
"resources": [
"secrets"
],
"provider": {
"keyArn": "arn:aws:kms:us-west-2:271345173787:key/6c3aafc1-dc99-4320-873f-5f5486f1b42a"
}
}
],
"health": {
"issues": []
},
"accessConfig": {
"authenticationMode": "API_AND_CONFIG_MAP"
},
"upgradePolicy": {
"supportType": "EXTENDED"
}
}
}[ 클러스터 기본정보 확인 ]

#
eksctl get cluster
NAME REGION EKSCTL CREATED
eksworkshop-eksctl us-west-2 False
eksctl get nodegroup --cluster $CLUSTER_NAME
CLUSTER NODEGROUP STATUS CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID ASG NAME TYPE
eksworkshop-eksctl blue-mng-20250325023020754500000029 ACTIVE 2025-03-25T02:30:22Z 1 2 1 m5.large,m6a.large,m6i.large AL2_x86_64 eks-blue-mng-20250325023020754500000029-00cae591-7abe-6143-dd33-c720df2700b6 managed
eksworkshop-eksctl initial-2025032502302076080000002c ACTIVE 2025-03-25T02:30:22Z 2 10 2 m5.large,m6a.large,m6i.large AL2_x86_64 eks-initial-2025032502302076080000002c-30cae591-7ac2-1e9c-2415-19975314b08b managed
eksctl get fargateprofile --cluster $CLUSTER_NAME
NAME SELECTOR_NAMESPACE SELECTOR_LABELS POD_EXECUTION_ROLE_ARN SUBNETS TAGS STATUS
fp-profile assets <none> arn:aws:iam::271345173787:role/fp-profile-2025032502301523520000001f subnet-0aeb12f673d69f7c5,subnet-047ab61ad85c50486,subnet-01bbd11a892aec6ee Blueprint=eksworkshop-eksctl,GithubRepo=github.com/aws-ia/terraform-aws-eks-blueprints,karpenter.sh/discovery=eksworkshop-eksctl ACTIVE
eksctl get addon --cluster $CLUSTER_NAME
NAME VERSION STATUS ISSUES IAMROLE UPDATE AVAILABLE CONFIGURATION VALUES
aws-ebs-csi-driver v1.41.0-eksbuild.1 ACTIVE 0 arn:aws:iam::271345173787:role/eksworkshop-eksctl-ebs-csi-driver-2025032502294618580000001d
coredns v1.8.7-eksbuild.10 ACTIVE 0 v1.9.3-eksbuild.22,v1.9.3-eksbuild.21,v1.9.3-eksbuild.19,v1.9.3-eksbuild.17,v1.9.3-eksbuild.15,v1.9.3-eksbuild.11,v1.9.3-eksbuild.10,v1.9.3-eksbuild.9,v1.9.3-eksbuild.7,v1.9.3-eksbuild.6,v1.9.3-eksbuild.5,v1.9.3-eksbuild.3,v1.9.3-eksbuild.2
kube-proxy v1.25.16-eksbuild.8 ACTIVE 0
vpc-cni v1.19.3-eksbuild.1 ACTIVE 0
#
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE LIFECYCLE CAPACITY-TYPE COMPUTE-TYPE
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 135m v1.25.16-eks-2d5f260 fargate
ip-10-0-12-228.us-west-2.compute.internal Ready <none> 145m v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 145m v1.25.16-eks-59bf375 self-managed
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 145m v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 135m v1.25.16-eks-59bf375 spot
ip-10-0-44-106.us-west-2.compute.internal Ready <none> 145m v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 145m v1.25.16-eks-59bf375 self-managed
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
NAME STATUS ROLES AGE VERSION NODEGROUP NODEPOOL
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 154m v1.25.16-eks-2d5f260
ip-10-0-12-228.us-west-2.compute.internal Ready <none> 163m v1.25.16-eks-59bf375 initial-2025032502302076080000002c
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 164m v1.25.16-eks-59bf375
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 163m v1.25.16-eks-59bf375 blue-mng-20250325023020754500000029
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 154m v1.25.16-eks-59bf375 default
ip-10-0-44-106.us-west-2.compute.internal Ready <none> 163m v1.25.16-eks-59bf375 initial-2025032502302076080000002c
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 164m v1.25.16-eks-59bf375
kubectl get nodepools
k get NAME NODECLASS
default default
kubectl get nodeclaims -o yaml
kubectl get nodeclaims
NAME TYPE ZONE NODE READY AGE
default-rpl9w c5.xlarge us-west-2c ip-10-0-39-95.us-west-2.compute.internal True 155m
kubectl get node --label-columns=node.kubernetes.io/instance-type,kubernetes.io/arch,kubernetes.io/os,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE ARCH OS ZONE
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 136m v1.25.16-eks-2d5f260 amd64 linux us-west-2c
ip-10-0-12-228.us-west-2.compute.internal Ready <none> 146m v1.25.16-eks-59bf375 m5.large amd64 linux us-west-2a
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 147m v1.25.16-eks-59bf375 m5.large amd64 linux us-west-2b
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 146m v1.25.16-eks-59bf375 m5.large amd64 linux us-west-2a
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 137m v1.25.16-eks-59bf375 c5.xlarge amd64 linux us-west-2c
ip-10-0-44-106.us-west-2.compute.internal Ready <none> 146m v1.25.16-eks-59bf375 m5.large amd64 linux us-west-2c
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 147m v1.25.16-eks-59bf375 m5.large amd64 linux us-west-2a
#
kubectl cluster-info
Kubernetes control plane is running at https://B852364D70EA6D62672481D278A15059.gr7.us-west-2.eks.amazonaws.com
CoreDNS is running at https://B852364D70EA6D62672481D278A15059.gr7.us-west-2.eks.amazonaws.com/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
#
kubectl get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 120m v1.25.16-eks-2d5f260 10.0.41.147 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
ip-10-0-12-228.us-west-2.compute.internal Ready <none> 130m v1.25.16-eks-59bf375 10.0.12.228 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 130m v1.25.16-eks-59bf375 10.0.26.119 <none> Amazon Linux 2 5.10.230-223.885.amzn2.x86_64 containerd://1.7.23
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 130m v1.25.16-eks-59bf375 10.0.3.199 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 120m v1.25.16-eks-59bf375 10.0.39.95 <none> Amazon Linux 2 5.10.230-223.885.amzn2.x86_64 containerd://1.7.23
ip-10-0-44-106.us-west-2.compute.internal Ready <none> 130m v1.25.16-eks-59bf375 10.0.44.106 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 130m v1.25.16-eks-59bf375 10.0.6.184 <none> Amazon Linux 2 5.10.230-223.885.amzn2.x86_64 containerd://1.7.23[ cluster & nodegroup 정보 확인 ]

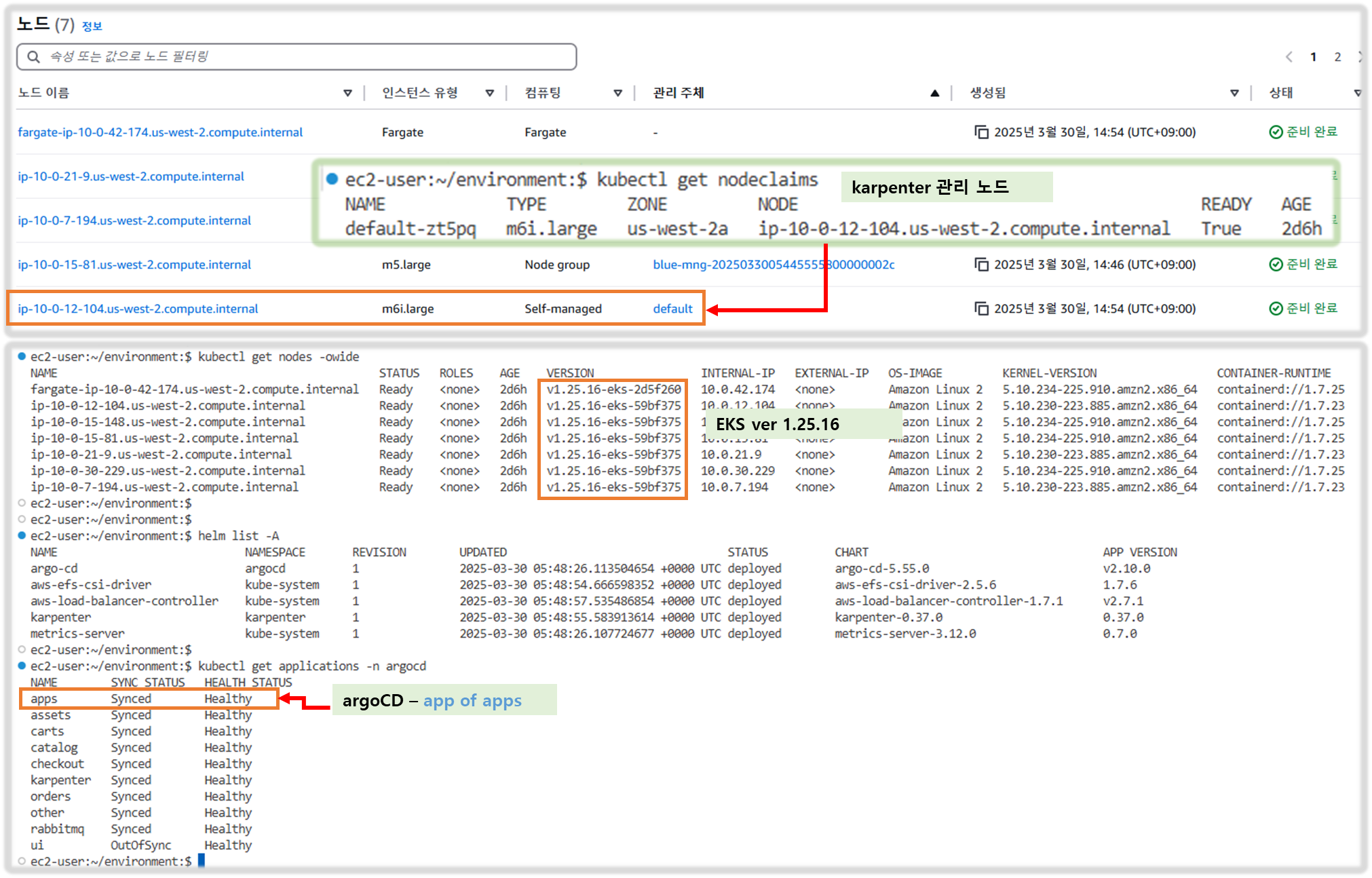
#
kubectl get crd
NAME CREATED AT
applications.argoproj.io 2025-03-25T02:34:49Z
applicationsets.argoproj.io 2025-03-25T02:34:49Z
appprojects.argoproj.io 2025-03-25T02:34:49Z
cninodes.vpcresources.k8s.aws 2025-03-25T02:26:13Z
ec2nodeclasses.karpenter.k8s.aws 2025-03-25T02:35:15Z
eniconfigs.crd.k8s.amazonaws.com 2025-03-25T02:27:35Z
ingressclassparams.elbv2.k8s.aws 2025-03-25T02:35:15Z
nodeclaims.karpenter.sh 2025-03-25T02:35:15Z
nodepools.karpenter.sh 2025-03-25T02:35:16Z
policyendpoints.networking.k8s.aws 2025-03-25T02:26:13Z
securitygrouppolicies.vpcresources.k8s.aws 2025-03-25T02:26:13Z
targetgroupbindings.elbv2.k8s.aws 2025-03-25T02:35:15Z
helm list -A
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
argo-cd argocd 1 2025-03-25 02:34:46.490919128 +0000 UTC deployed argo-cd-5.55.0 v2.10.0
aws-efs-csi-driver kube-system 1 2025-03-25 02:35:16.380271414 +0000 UTC deployed aws-efs-csi-driver-2.5.6 1.7.6
aws-load-balancer-controller kube-system 1 2025-03-25 02:35:17.147637895 +0000 UTC deployed aws-load-balancer-controller-1.7.1 v2.7.1
karpenter karpenter 1 2025-03-25 02:35:16.452581818 +0000 UTC deployed karpenter-0.37.0 0.37.0
metrics-server kube-system 1 2025-03-25 02:34:46.480366515 +0000 UTC deployed metrics-server-3.12.0 0.7.0
kubectl get applications -n argocd
NAME SYNC STATUS HEALTH STATUS
apps Synced Healthy
assets Synced Healthy
carts Synced Healthy
catalog Synced Healthy
checkout Synced Healthy
karpenter Synced Healthy
orders Synced Healthy
other Synced Healthy
rabbitmq Synced Healthy
ui OutOfSync Healthy
#
kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
argocd argo-cd-argocd-application-controller-0 1/1 Running 0 146m
argocd argo-cd-argocd-applicationset-controller-74d9c9c5c7-6bsk8 1/1 Running 0 146m
argocd argo-cd-argocd-dex-server-6dbbd57479-h8r6b 1/1 Running 0 146m
argocd argo-cd-argocd-notifications-controller-fb4b954d5-lvp2z 1/1 Running 0 146m
argocd argo-cd-argocd-redis-76b4c599dc-5gj95 1/1 Running 0 146m
argocd argo-cd-argocd-repo-server-6b777b579d-thwrk 1/1 Running 0 146m
argocd argo-cd-argocd-server-86bdbd7b89-8t6f5 1/1 Running 0 146m
assets assets-7ccc84cb4d-s8wwb 1/1 Running 0 141m
carts carts-7ddbc698d8-zts9k 1/1 Running 0 141m
carts carts-dynamodb-6594f86bb9-8pzk5 1/1 Running 0 141m
catalog catalog-857f89d57d-9nfnw 1/1 Running 3 (140m ago) 141m
catalog catalog-mysql-0 1/1 Running 0 141m
checkout checkout-558f7777c-fs8dk 1/1 Running 0 141m
checkout checkout-redis-f54bf7cb5-whk4r 1/1 Running 0 141m
karpenter karpenter-547d656db9-qzfmm 1/1 Running 0 146m
karpenter karpenter-547d656db9-tsg8n 1/1 Running 0 146m
kube-system aws-load-balancer-controller-774bb546d8-pphh5 1/1 Running 0 145m
kube-system aws-load-balancer-controller-774bb546d8-r7k45 1/1 Running 0 145m
kube-system aws-node-6xgbd 2/2 Running 0 140m
kube-system aws-node-j5qzk 2/2 Running 0 145m
kube-system aws-node-mvg22 2/2 Running 0 145m
kube-system aws-node-pnx48 2/2 Running 0 145m
kube-system aws-node-sh8lt 2/2 Running 0 145m
kube-system aws-node-z7g8q 2/2 Running 0 145m
kube-system coredns-98f76fbc4-4wz5j 1/1 Running 0 145m
kube-system coredns-98f76fbc4-k4wnz 1/1 Running 0 145m
kube-system ebs-csi-controller-6b575b5f4d-dqdqp 6/6 Running 0 145m
kube-system ebs-csi-controller-6b575b5f4d-wwc7q 6/6 Running 0 145m
kube-system ebs-csi-node-72rl8 3/3 Running 0 145m
kube-system ebs-csi-node-g6cn4 3/3 Running 0 145m
kube-system ebs-csi-node-jvrwj 3/3 Running 0 145m
kube-system ebs-csi-node-jwndw 3/3 Running 0 145m
kube-system ebs-csi-node-qqmsh 3/3 Running 0 145m
kube-system ebs-csi-node-qwpf5 3/3 Running 0 140m
kube-system efs-csi-controller-5d74ddd947-97ncr 3/3 Running 0 146m
kube-system efs-csi-controller-5d74ddd947-mzkqd 3/3 Running 0 146m
kube-system efs-csi-node-69hzl 3/3 Running 0 140m
kube-system efs-csi-node-6k8g2 3/3 Running 0 146m
kube-system efs-csi-node-8hvhz 3/3 Running 0 146m
kube-system efs-csi-node-9fnxz 3/3 Running 0 146m
kube-system efs-csi-node-gb2xm 3/3 Running 0 146m
kube-system efs-csi-node-rcggq 3/3 Running 0 146m
kube-system kube-proxy-6b9vq 1/1 Running 0 145m
kube-system kube-proxy-6lqcc 1/1 Running 0 145m
kube-system kube-proxy-9x46z 1/1 Running 0 145m
kube-system kube-proxy-k26rj 1/1 Running 0 145m
kube-system kube-proxy-xk9tc 1/1 Running 0 145m
kube-system kube-proxy-xvh4j 1/1 Running 0 140m
kube-system metrics-server-785cd745cd-c57q7 1/1 Running 0 146m
orders orders-5b97745747-mxg72 1/1 Running 2 (140m ago) 141m
orders orders-mysql-b9b997d9d-2p8pn 1/1 Running 0 141m
rabbitmq rabbitmq-0 1/1 Running 0 141m
ui ui-5dfb7d65fc-9vgt9 1/1 Running 0 141m
#
kubectl get pdb -A
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
karpenter karpenter N/A 1 1 145m
kube-system aws-load-balancer-controller N/A 1 1 145m
kube-system coredns N/A 1 1 153m
kube-system ebs-csi-controller N/A 1 1 145m
#
kubectl get svc -n argocd argo-cd-argocd-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argo-cd-argocd-server LoadBalancer 172.20.10.210 k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com 80:32065/TCP,443:31156/TCP 150m
kubectl get targetgroupbindings -n argocd
NAME SERVICE-NAME SERVICE-PORT TARGET-TYPE AGE
k8s-argocd-argocdar-9c77afbc38 argo-cd-argocd-server 443 ip 153m
k8s-argocd-argocdar-efa4621491 argo-cd-argocd-server 80 ip 153m
# 노드에 taint 정보 확인
kubectl get nodes -o custom-columns='NODE:.metadata.name,TAINTS:.spec.taints[*].key,VALUES:.spec.taints[*].value,EFFECTS:.spec.taints[*].effect'
NODE TAINTS VALUES EFFECTS
fargate-ip-10-0-2-38.us-west-2.compute.internal eks.amazonaws.com/compute-type fargate NoSchedule
ip-10-0-0-72.us-west-2.compute.internal dedicated CheckoutApp NoSchedule
ip-10-0-13-217.us-west-2.compute.internal <none> <none> <none>
ip-10-0-28-252.us-west-2.compute.internal <none> <none> <none>
ip-10-0-3-168.us-west-2.compute.internal dedicated OrdersApp NoSchedule
ip-10-0-40-107.us-west-2.compute.internal <none> <none> <none>
ip-10-0-42-84.us-west-2.compute.internal <none> <none> <none>
#
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
NAME STATUS ROLES AGE VERSION NODEGROUP NODEPOOL
fargate-ip-10-0-2-38.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-2d5f260
ip-10-0-0-72.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-59bf375 default
ip-10-0-13-217.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-59bf375 initial-2025032812112870770000002c
ip-10-0-28-252.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-59bf375
ip-10-0-3-168.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-59bf375 blue-mng-20250328121128698500000029
ip-10-0-40-107.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-59bf375
ip-10-0-42-84.us-west-2.compute.internal Ready <none> 16h v1.25.16-eks-59bf375 initial-2025032812112870770000002c
# 노드 별 label 확인
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, labels: .metadata.labels}'
...
{
"name": "ip-10-0-0-72.us-west-2.compute.internal",
"labels": {
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/instance-type": "m5.large",
"beta.kubernetes.io/os": "linux",
"env": "dev",
...
#
kubectl get sts -A
NAMESPACE NAME READY AGE
argocd argo-cd-argocd-application-controller 1/1 150m
catalog catalog-mysql 1/1 145m
rabbitmq rabbitmq 1/1 145m
#
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
efs efs.csi.aws.com Delete Immediate true 152m
gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 163m
gp3 (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 152m
kubectl describe sc efs
...
Provisioner: efs.csi.aws.com
Parameters: basePath=/dynamic_provisioning,directoryPerms=755,ensureUniqueDirectory=false,fileSystemId=fs-0b269b8e2735b9c59,gidRangeEnd=200,gidRangeStart=100,provisioningMode=efs-ap,reuseAccessPoint=false,subPathPattern=${.PVC.namespace}/${.PVC.name}
AllowVolumeExpansion: True
...
#
kubectl get pv,pvc -A
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-7aa7d213-892d-4f79-bf90-a530d648ff63 4Gi RWO Delete Bound catalog/catalog-mysql-pvc gp3 146m
persistentvolume/pvc-875d1ca7-e28b-421a-8a7e-2ae9d7480b9a 4Gi RWO Delete Bound orders/order-mysql-pvc gp3 146m
persistentvolume/pvc-b612df9f-bb9d-4b82-a973-fe40360c2ef5 4Gi RWO Delete Bound checkout/checkout-redis-pvc gp3 145m
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
catalog persistentvolumeclaim/catalog-mysql-pvc Bound pvc-7aa7d213-892d-4f79-bf90-a530d648ff63 4Gi RWO gp3 146m
checkout persistentvolumeclaim/checkout-redis-pvc Bound pvc-b612df9f-bb9d-4b82-a973-fe40360c2ef5 4Gi RWO gp3 146m
orders persistentvolumeclaim/order-mysql-pvc Bound pvc-875d1ca7-e28b-421a-8a7e-2ae9d7480b9a 4Gi RWO gp3 146m[ access entry 및 IAM Roll 매핑정보 확인 ]
#
aws eks list-access-entries --cluster-name $CLUSTER_NAME
{
"accessEntries": [
"arn:aws:iam::271345173787:role/aws-service-role/eks.amazonaws.com/AWSServiceRoleForAmazonEKS",
"arn:aws:iam::271345173787:role/blue-mng-eks-node-group-20250325022024229600000010",
"arn:aws:iam::271345173787:role/default-selfmng-node-group-2025032502202377680000000e",
"arn:aws:iam::271345173787:role/fp-profile-2025032502301523520000001f",
"arn:aws:iam::271345173787:role/initial-eks-node-group-2025032502202398930000000f",
"arn:aws:iam::271345173787:role/karpenter-eksworkshop-eksctl",
"arn:aws:iam::271345173787:role/workshop-stack-IdeIdeRoleD654ADD4-Qhv1nLkOGItJ"
]
}
#
eksctl get iamidentitymapping --cluster $CLUSTER_NAME
ARN USERNAME GROUPS ACCOUNT
arn:aws:iam::271345173787:role/WSParticipantRole admin system:masters
arn:aws:iam::271345173787:role/blue-mng-eks-node-group-20250325022024229600000010 system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
arn:aws:iam::271345173787:role/fp-profile-2025032502301523520000001f system:node:{{SessionName}} system:bootstrappers,system:nodes,system:node-proxier
arn:aws:iam::271345173787:role/initial-eks-node-group-2025032502202398930000000f system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
arn:aws:iam::271345173787:role/workshop-stack-IdeIdeRoleD654ADD4-Qhv1nLkOGItJ admin system:masters
#
kubectl describe cm -n kube-system aws-auth
...
mapRoles:
----
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::271345173787:role/blue-mng-eks-node-group-20250325022024229600000010
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::271345173787:role/initial-eks-node-group-2025032502202398930000000f
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:bootstrappers
- system:nodes
- system:node-proxier
rolearn: arn:aws:iam::271345173787:role/fp-profile-2025032502301523520000001f
username: system:node:{{SessionName}}
- groups:
- system:masters
rolearn: arn:aws:iam::271345173787:role/WSParticipantRole
username: admin
- groups:
- system:masters
rolearn: arn:aws:iam::271345173787:role/workshop-stack-IdeIdeRoleD654ADD4-Qhv1nLkOGItJ
username: admin
...
# IRSA : karpenter, alb-controller, ebs-csi-driver, aws-efs-csi-driver 4곳에서 사용
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
kubectl describe sa -A | grep role-arn
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::363835126563:role/karpenter-2025032812153665450000003a
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::363835126563:role/alb-controller-20250328121536592300000039
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::363835126563:role/eksworkshop-eksctl-ebs-csi-driver-2025032812105428630000001d
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::363835126563:role/aws-efs-csi-driver-2025032812153665870000003b
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::363835126563:role/aws-efs-csi-driver-2025032812153665870000003b
# pod identity 없음
eksctl get podidentityassociation --cluster $CLUSTER_NAME
# EKS API Endpoint
aws eks describe-cluster --name $CLUSTER_NAME | jq -r .cluster.endpoint | cut -d '/' -f 3
B852364D70EA6D62672481D278A15059.gr7.us-west-2.eks.amazonaws.com
dig +short $APIDNS
35.163.123.202
44.246.155.206
# OIDC
aws eks describe-cluster --name $CLUSTER_NAME --query cluster.identity.oidc.issuer --output text
https://oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059
aws iam list-open-id-connect-providers | jq
{
"OpenIDConnectProviderList": [
{
"Arn": "arn:aws:iam::363835126563:oidc-provider/oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059"
}
]
}

* Blue-Green 업그레이드 시, IRSA (OpenID Connector provider URL) 도 변경된다!!
Step3. AWS 관리 콘솔 접속 : EKS, EC2, VPC 등 확인
☞ EKS > Compute / Add-on
☞ EKS - Upgrade version : 상위 1개 마이너 버전 업그레이드만 가능. 실제 수행은 하지 말것!
☞ EKS - Dashboard - Cluster insights : Deprecated APIs remove in Kubernetes 1.26 클릭 상세 확인
☞ EC2 : IDE-Server 제외한, (워커) 노드 6대 EC2 확인 ← 참고로 fargate node(MicroVM) 1대 기동 중
☞ EC2 - LB : ArgoCD 외부 접속용 NLB 확인
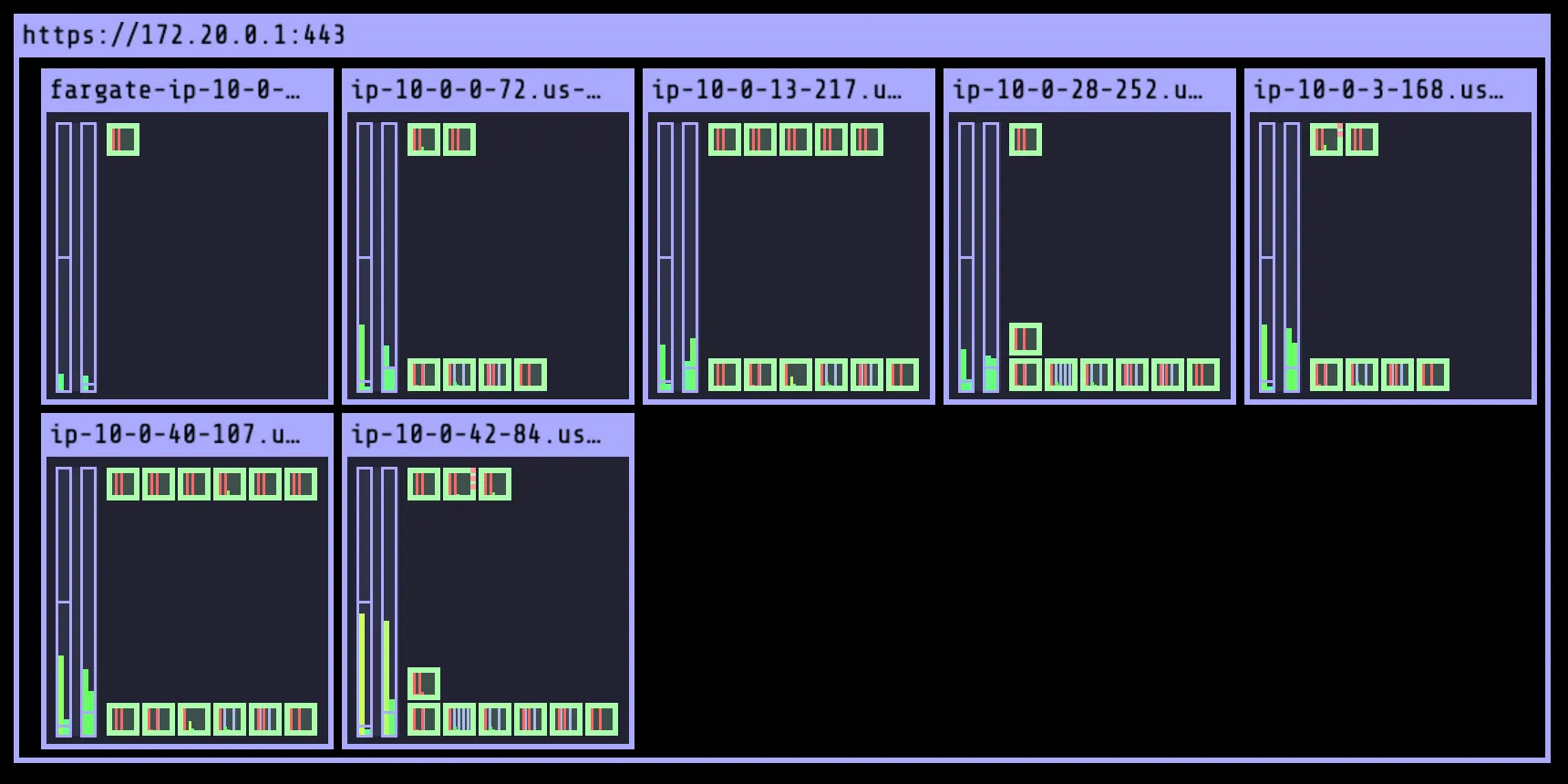
☞ EC2 - ASG : 3개의 ASG 확인 - blug-mng 관리 노드는 AZ1 곳만 사용 중(us-west-2a)


Step4. (추가) 실습 편리 설정 : kube-ops-view , krew , eks-node-view , k9s
1. Kube-OpsView 설치
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm repo update
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --namespace kube-system
#
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-type: external
labels:
app.kubernetes.io/instance: kube-ops-view
app.kubernetes.io/name: kube-ops-view
name: kube-ops-view-nlb
namespace: kube-system
spec:
type: LoadBalancer
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/instance: kube-ops-view
app.kubernetes.io/name: kube-ops-view
EOF
# kube-ops-view 접속 URL 확인 (1.5, 1.3 배율)
kubectl get svc -n kube-system kube-ops-view-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "KUBE-OPS-VIEW URL = http://"$1"/#scale=1.5"}'
kubectl get svc -n kube-system kube-ops-view-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "KUBE-OPS-VIEW URL = http://"$1"/#scale=1.3"}'
2. krew 설치
# 설치
(
set -x; cd "$(mktemp -d)" &&
OS="$(uname | tr '[:upper:]' '[:lower:]')" &&
ARCH="$(uname -m | sed -e 's/x86_64/amd64/' -e 's/\(arm\)\(64\)\?.*/\1\2/' -e 's/aarch64$/arm64/')" &&
KREW="krew-${OS}_${ARCH}" &&
curl -fsSLO "https://github.com/kubernetes-sigs/krew/releases/latest/download/${KREW}.tar.gz" &&
tar zxvf "${KREW}.tar.gz" &&
./"${KREW}" install krew
)
# PATH
export PATH="${KREW_ROOT:-$HOME/.krew}/bin:$PATH"
vi ~/.bashrc
-----------
export PATH="${KREW_ROOT:-$HOME/.krew}/bin:$PATH"
-----------
# 플러그인 설치
kubectl krew install ctx ns df-pv get-all neat stern oomd whoami rbac-tool rolesum
kubectl krew list
#
kubectl df-pv
#
kubectl whoami --all
User: admin
Groups:
system:masters
system:authenticated
ARN:
arn:aws:sts::363835126563:assumed-role/workshop-stack-IdeIdeRoleD654ADD4-nSApoLMDr5GW/i-00d9a1ac022bd4f29
3. eks-node-view
# 설치
wget -O eks-node-viewer https://github.com/awslabs/eks-node-viewer/releases/download/v0.7.1/eks-node-viewer_Linux_x86_64
chmod +x eks-node-viewer
sudo mv -v eks-node-viewer /usr/local/bin
# Standard usage : self-mng 노드는 가격 미출력됨.
eks-node-viewer
ip-10-0-40-107.us-west-2.compute.internal cpu ██████████░░░░░░░░░░░░░░░░░░░░░░░░░ 27% (12 pods) m5.large - - Ready
ip-10-0-28-252.us-west-2.compute.internal cpu ████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 12% (8 pods) m5.large - - Ready
ip-10-0-3-168.us-west-2.compute.internal cpu ████████░░░░░░░░░░░░░░░░░░░░░░░░░░░ 22% (6 pods) m5.large/$0.0960 On-Demand - Ready
ip-10-0-13-217.us-west-2.compute.internal cpu █████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 15% (11 pods) m5.large/$0.0960 On-Demand - Ready
ip-10-0-42-84.us-west-2.compute.internal cpu ███████████████░░░░░░░░░░░░░░░░░░░░ 44% (10 pods) m5.large/$0.0960 On-Demand - Ready
ip-10-0-0-72.us-west-2.compute.internal cpu ████████░░░░░░░░░░░░░░░░░░░░░░░░░░░ 22% (6 pods) m5.large/$0.0378 Spot - Ready
fargate-ip-10-0-2-38.us-west-2.compute.internal cpu ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 6% (1 pods) 0.25vCPU-0.5GB/$0.0123 Fargate - Ready
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE LIFECYCLE CAPACITY-TYPE COMPUTE-TYPE
fargate-ip-10-0-2-38.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-2d5f260 fargate
ip-10-0-0-72.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-59bf375 spot
ip-10-0-13-217.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-28-252.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-59bf375 self-managed
ip-10-0-3-168.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-40-107.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-59bf375 self-managed
ip-10-0-42-84.us-west-2.compute.internal Ready <none> 18h v1.25.16-eks-59bf375 ON_DEMAND
# Display both CPU and Memory Usage
eks-node-viewer --resources cpu,memory
eks-node-viewer --resources cpu,memory --extra-labels eks-node-viewer/node-age
# Display extra labels, i.e. AZ : node 에 labels 사용 가능
eks-node-viewer --extra-labels topology.kubernetes.io/zone
eks-node-viewer --extra-labels kubernetes.io/arch
# Sort by CPU usage in descending order
eks-node-viewer --node-sort=eks-node-viewer/node-cpu-usage=dsc
# Karenter nodes only
eks-node-viewer --node-selector "karpenter.sh/provisioner-name"
# Specify a particular AWS profile and region
AWS_PROFILE=myprofile AWS_REGION=us-west-2
Computed Labels : --extra-labels
# eks-node-viewer/node-age - Age of the node
eks-node-viewer --extra-labels eks-node-viewer/node-age
eks-node-viewer --extra-labels topology.kubernetes.io/zone,eks-node-viewer/node-age
# eks-node-viewer/node-ephemeral-storage-usage - Ephemeral Storage usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-ephemeral-storage-usage
# eks-node-viewer/node-cpu-usage - CPU usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-cpu-usage
# eks-node-viewer/node-memory-usage - Memory usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-memory-usage
# eks-node-viewer/node-pods-usage - Pod usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-pods-usage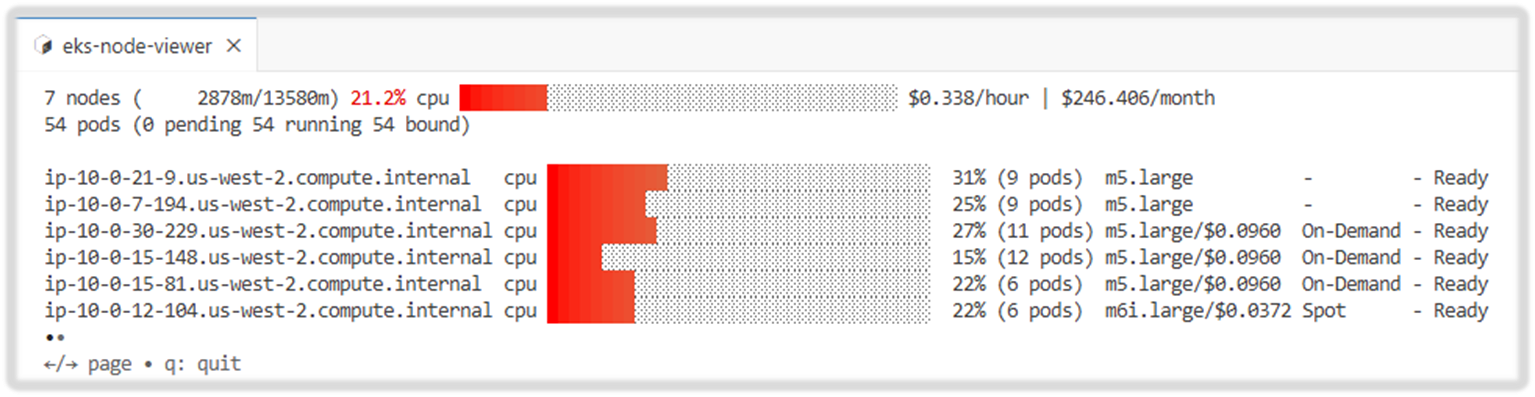
4. k9s
#
curl -sS https://webinstall.dev/k9s | bash
k9s version
#
k9s
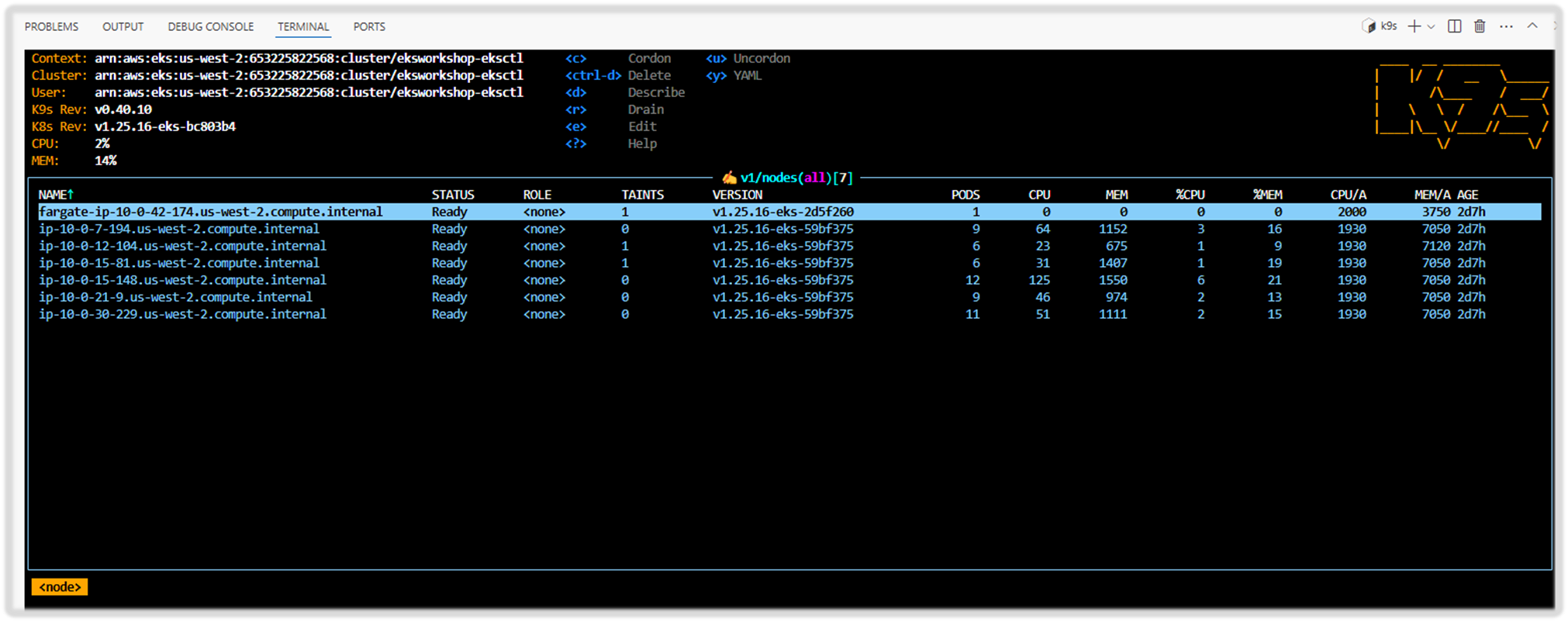
Step5. 실습 환경 배포한 테라폼 파일 확인 : 업그레이드 작업에서 사용 예정
# 파일 확인
ec2-user:~/environment:$ ls -lrt terraform/
total 40
-rw-r--r--. 1 ec2-user ec2-user 625 Aug 27 2024 vpc.tf
-rw-r--r--. 1 ec2-user ec2-user 542 Aug 27 2024 versions.tf
-rw-r--r--. 1 ec2-user ec2-user 353 Aug 27 2024 variables.tf
-rw-r--r--. 1 ec2-user ec2-user 282 Aug 27 2024 outputs.tf
-rw-r--r--. 1 ec2-user ec2-user 1291 Aug 27 2024 gitops-setup.tf
-rw-r--r--. 1 ec2-user ec2-user 4512 Feb 5 01:15 base.tf
-rw-r--r--. 1 ec2-user ec2-user 5953 Feb 13 19:55 addons.tf
-rw-r--r--. 1 ec2-user ec2-user 33 Mar 25 02:26 backend_override.tf
# 해당 경로에 tfstate 파일은 없다.
ec2-user:~/environment/terraform:$ terraform output
╷
│ Warning: No outputs found
#
aws s3 ls
2025-03-28 11:56:25 workshop-stack-tfstatebackendbucketf0fc9a9d-wt2fbt9qjdpc
aws s3 ls s3://workshop-stack-tfstatebackendbucketf0fc9a9d-wt2fbt9qjdpc
2025-03-28 12:18:23 940996 terraform.tfstate
# (옵션) terraform.tfstate 복사 후 IDE-Server 에서 terraform.tfstate 열어보기
aws s3 cp s3://workshop-stack-tfstatebackendbucketf0fc9a9d-wt2fbt9qjdpc/terraform.tfstate .
# backend_override.tf 수정
terraform {
backend "s3" {
bucket = "workshop-stack-tfstatebackendbucketf0fc9a9d-shrn1gryae5i"
region = "us-west-2"
key = "terraform.tfstate"
}
}
# 확인
terraform state list
terrafor
▶ vpc.tf
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 5.0"
name = local.name
cidr = local.vpc_cidr
azs = local.azs
private_subnets = [for k, v in local.azs : cidrsubnet(local.vpc_cidr, 4, k)]
public_subnets = [for k, v in local.azs : cidrsubnet(local.vpc_cidr, 8, k + 48)]
enable_nat_gateway = true
single_nat_gateway = true
public_subnet_tags = {
"kubernetes.io/role/elb" = 1
}
private_subnet_tags = {
"kubernetes.io/role/internal-elb" = 1
# Tags subnets for Karpenter auto-discovery
"karpenter.sh/discovery" = local.name
}
tags = local.tags
}
▶ versions.tf
terraform {
required_version = ">= 1.3"
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 5.34"
}
helm = {
source = "hashicorp/helm"
version = ">= 2.9"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.20"
}
}
# ## Used for end-to-end testing on project; update to suit your needs
# backend "s3" {
# bucket = "terraform-ssp-github-actions-state"
# region = "us-west-2"
# key = "e2e/karpenter/terraform.tfstate"
# }
}
▶ variables.tf : eks 버전(1.25), mng(1.25)
variable "cluster_version" {
description = "EKS cluster version."
type = string
default = "1.25"
}
variable "mng_cluster_version" {
description = "EKS cluster mng version."
type = string
default = "1.25"
}
variable "ami_id" {
description = "EKS AMI ID for node groups"
type = string
default = ""
}
▶ outputs.tf
output "configure_kubectl" {
description = "Configure kubectl: make sure you're logged in with the correct AWS profile and run the following command to update your kubeconfig"
value = "aws eks --region ${local.region} update-kubeconfig --name ${module.eks.cluster_name}"
}▶ gitops-setup.tf : aws_codecommit (Private Git Repo, 관리형 소스 제어 서비스) - Link
resource "aws_codecommit_repository" "gitops_repo_cc" {
repository_name = "eks-gitops-repo"
default_branch = "main"
}
resource "aws_iam_user" "argocd_user" {
name = "argocd-user"
}
resource "aws_iam_service_specific_credential" "argocd_codecommit_credential" {
service_name = "codecommit.amazonaws.com"
user_name = aws_iam_user.argocd_user.name
}
resource "aws_iam_user_policy" "argocd_user_codecommit_rw" {
name = "argocd-user-codecommit-ro"
user = aws_iam_user.argocd_user.name
policy = jsonencode({
Version : "2012-10-17",
Statement : [
{
Effect : "Allow",
Action : "codecommit:*",
Resource : aws_codecommit_repository.gitops_repo_cc.arn
}
]
})
}
resource "aws_secretsmanager_secret" "argocd_user_creds_secret" {
name = "argocd-user-creds"
}
resource "aws_secretsmanager_secret_version" "argocd_user_creds_secret_version" {
secret_id = aws_secretsmanager_secret.argocd_user_creds_secret.id
secret_string = jsonencode({
url = "${aws_codecommit_repository.gitops_repo_cc.clone_url_http}"
username = "${aws_iam_service_specific_credential.argocd_codecommit_credential.service_user_name}"
password = "${aws_iam_service_specific_credential.argocd_codecommit_credential.service_password}"
})
}▶ base.tf
provider "aws" {
region = local.region
}
# Required for public ECR where Karpenter artifacts are hosted
provider "aws" {
region = "us-east-1"
alias = "virginia"
}
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
provider "helm" {
kubernetes {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
}
data "aws_partition" "current" {}
data "aws_caller_identity" "current" {}
data "aws_ecrpublic_authorization_token" "token" {
provider = aws.virginia
}
data "aws_availability_zones" "available" {}
# tflint-ignore: terraform_unused_declarations
variable "eks_cluster_id" {
description = "EKS cluster name"
type = string
}
variable "aws_region" {
description = "AWS Region"
type = string
}
locals {
name = var.eks_cluster_id
region = var.aws_region
vpc_cidr = "10.0.0.0/16"
azs = slice(data.aws_availability_zones.available.names, 0, 3)
tags = {
Blueprint = local.name
GithubRepo = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
}
################################################################################
# Cluster
################################################################################
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.14"
cluster_name = local.name
cluster_version = var.cluster_version
cluster_endpoint_public_access = true
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
# Fargate profiles use the cluster primary security group so these are not utilized
# create_cluster_security_group = false
# create_node_security_group = false
enable_cluster_creator_admin_permissions = true
fargate_profiles = {
fp-profile = {
selectors = [
{ namespace = "assets" }
]
}
}
eks_managed_node_group_defaults = {
cluster_version = var.mng_cluster_version
}
eks_managed_node_groups = {
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
update_config = {
max_unavailable_percentage = 35
}
}
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]]
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
}
# For demonstrating node-termination-handler
self_managed_node_groups = {
default-selfmng = {
instance_type = "m5.large"
min_size = 1
max_size = 2
desired_size = 2
# Additional configurations
ami_id = "ami-0ee947a6f4880da75" # Replace with your desired AMI ID
subnet_ids = module.vpc.private_subnets
disk_size = 100
# Optional
bootstrap_extra_args = "--kubelet-extra-args '--node-labels=node.kubernetes.io/lifecycle=self-managed,team=carts'"
# Required for self-managed node groups
create_launch_template = true
launch_template_use_name_prefix = true
}
}
tags = merge(local.tags, {
# NOTE - if creating multiple security groups with this module, only tag the
# security group that Karpenter should utilize with the following tag
# (i.e. - at most, only one security group should have this tag in your account)
"karpenter.sh/discovery" = local.name
})
}
resource "time_sleep" "wait_60_seconds" {
create_duration = "60s"
depends_on = [module.eks]
}
▶ backend_override.tf : s3 정보 추가해서 사용 할 것
terraform {
backend "s3" {}
}
▶ addons.tf
################################################################################
# EKS Blueprints Addons
################################################################################
module "eks_blueprints_addons" {
depends_on = [ time_sleep.wait_60_seconds ]
source = "aws-ia/eks-blueprints-addons/aws"
version = "~> 1.16"
cluster_name = module.eks.cluster_name
cluster_endpoint = module.eks.cluster_endpoint
cluster_version = module.eks.cluster_version
oidc_provider_arn = module.eks.oidc_provider_arn
# We want to wait for the Fargate profiles to be deployed first
create_delay_dependencies = [for prof in module.eks.fargate_profiles : prof.fargate_profile_arn]
eks_addons = {
coredns = {
addon_version = "v1.8.7-eksbuild.10"
}
kube-proxy = {
addon_version = "v1.25.16-eksbuild.8"
}
vpc-cni = {
most_recent = true
}
aws-ebs-csi-driver = {
service_account_role_arn = module.ebs_csi_driver_irsa.iam_role_arn
}
}
enable_karpenter = true
enable_aws_efs_csi_driver = true
enable_argocd = true
enable_aws_load_balancer_controller = true
enable_metrics_server = true
argocd = {
set = [
{
name = "server.service.type"
value = "LoadBalancer"
},
{
name = "server.service.annotations.service\\.beta\\.kubernetes\\.io/aws-load-balancer-scheme"
value = "internet-facing"
},
{
name = "server.service.annotations.service\\.beta\\.kubernetes\\.io/aws-load-balancer-type"
value = "external"
},
{
name = "server.service.annotations.service\\.beta\\.kubernetes\\.io/aws-load-balancer-nlb-target-type"
value = "ip"
}
]
wait = true
}
aws_load_balancer_controller = {
set = [
{
name = "vpcId"
value = module.vpc.vpc_id
},
{
name = "region"
value = local.region
},
{
name = "podDisruptionBudget.maxUnavailable"
value = 1
},
{
name = "enableServiceMutatorWebhook"
value = "false"
}
]
wait = true
}
karpenter_node = {
# Use static name so that it matches what is defined in `karpenter.yaml` example manifest
iam_role_use_name_prefix = false
}
tags = local.tags
}
resource "time_sleep" "wait_90_seconds" {
create_duration = "90s"
depends_on = [module.eks_blueprints_addons]
}
resource "aws_eks_access_entry" "karpenter_node_access_entry" {
cluster_name = module.eks.cluster_name
principal_arn = module.eks_blueprints_addons.karpenter.node_iam_role_arn
# kubernetes_groups = []
type = "EC2_LINUX"
lifecycle {
ignore_changes = [
user_name
]
}
}
################################################################################
# Supporting Resources
################################################################################
module "ebs_csi_driver_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "~> 5.20"
role_name_prefix = "${module.eks.cluster_name}-ebs-csi-driver-"
attach_ebs_csi_policy = true
oidc_providers = {
main = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["kube-system:ebs-csi-controller-sa"]
}
}
tags = local.tags
}
module "efs" {
source = "terraform-aws-modules/efs/aws"
version = "~> 1.1"
creation_token = local.name
name = local.name
# Mount targets / security group
mount_targets = {
for k, v in zipmap(local.azs, module.vpc.private_subnets) : k => { subnet_id = v }
}
security_group_description = "${local.name} EFS security group"
security_group_vpc_id = module.vpc.vpc_id
security_group_rules = {
vpc = {
# relying on the defaults provided for EFS/NFS (2049/TCP + ingress)
description = "NFS ingress from VPC private subnets"
cidr_blocks = module.vpc.private_subnets_cidr_blocks
}
}
tags = local.tags
}
################################################################################
# Storage Classes
################################################################################
resource "kubernetes_annotations" "gp2" {
api_version = "storage.k8s.io/v1"
kind = "StorageClass"
# This is true because the resources was already created by the ebs-csi-driver addon
force = "true"
metadata {
name = "gp2"
}
annotations = {
# Modify annotations to remove gp2 as default storage class still retain the class
"storageclass.kubernetes.io/is-default-class" = "false"
}
depends_on = [
module.eks_blueprints_addons
]
}
resource "kubernetes_storage_class_v1" "gp3" {
metadata {
name = "gp3"
annotations = {
# Annotation to set gp3 as default storage class
"storageclass.kubernetes.io/is-default-class" = "true"
}
}
storage_provisioner = "ebs.csi.aws.com"
allow_volume_expansion = true
reclaim_policy = "Delete"
volume_binding_mode = "WaitForFirstConsumer"
parameters = {
encrypted = true
fsType = "ext4"
type = "gp3"
}
depends_on = [
module.eks_blueprints_addons
]
}
# done: update parameters
resource "kubernetes_storage_class_v1" "efs" {
metadata {
name = "efs"
}
storage_provisioner = "efs.csi.aws.com"
reclaim_policy = "Delete"
parameters = {
provisioningMode = "efs-ap"
fileSystemId = module.efs.id
directoryPerms = "755"
gidRangeStart = "100" # optional
gidRangeEnd = "200" # optional
basePath = "/dynamic_provisioning" # optional
subPathPattern = "$${.PVC.namespace}/$${.PVC.name}" # optional
ensureUniqueDirectory = "false" # optional
reuseAccessPoint = "false" # optional
}
mount_options = [
"iam"
]
depends_on = [
module.eks_blueprints_addons
]
}
Step6. Sample application : UI Service(NLB) 설정 - ArgoCD (admin , UeVOwZPdX77bTn8C)
* argoCD 초기 비밀번호 확인방법
kubectl -n <argocd-namespace> get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 --decode- 샘플 애플리케이션은 고객이 카탈로그를 탐색하고 장바구니에 항목을 추가하며 결제 프로세스를 통해 주문을 완료할 수 있는 간단한 웹 스토어 애플리케이션
- 애플리케이션에는 여러 구성 요소와 종속성이 있습니다:

|
Component
|
Description |
| UI` | Provides the front end user interface and aggregates API calls to the various other services. |
|
Catalog
|
API for product listings and details
|
|
Cart
|
API for customer shopping carts
|
|
Checkout
|
API to orchestrate the checkout process
|
|
Orders
|
API to receive and process customer orders
|
|
Static assets
|
Serves static assets like images related to the product catalog
|
- 이미지 도커파일과, ECR 공개 저장소 정보 - Link
- 처음에는 로드 밸런서나 관리형 데이터베이스와 같은 AWS 서비스를 사용하지 않고 Amazon EKS 클러스터에 자체적으로 포함된 방식으로 애플리케이션을 배포할 것입니다.
- 실험 과정에서 EKS의 다양한 기능을 활용하여 소매점의 광범위한 AWS 서비스와 기능을 활용할 것입니다.
- 모든 구성 요소는 ArgoCD를 사용하여 EKS 클러스터에 배포됩니다.
- AWS CodeCommit 저장소를 GitOps repo로 사용하여 IDE에 복제할 수 있도록 했습니다.
#
cd ~/environment
git clone codecommit::${REGION}://eks-gitops-repo
#
sudo yum install tree -y
tree eks-gitops-repo/ -L 2
eks-gitops-repo/
├── app-of-apps
│ ├── Chart.yaml
│ ├── templates
│ └── values.yaml
└── apps
├── assets
├── carts
├── catalog
├── checkout
├── karpenter
├── kustomization.yaml
├── orders
├── other
├── rabbitmq
└── ui
# Login to ArgoCD Console using credentials from following commands:
export ARGOCD_SERVER=$(kubectl get svc argo-cd-argocd-server -n argocd -o json | jq --raw-output '.status.loadBalancer.ingress[0].hostname')
echo "ArgoCD URL: http://${ARGOCD_SERVER}"
ArgoCD URL: http://k8s-argocd-argocdar-01634fea43-3cdeb4d8a7e05ff9.elb.us-west-2.amazonaws.com
export ARGOCD_USER="admin"
export ARGOCD_PWD=$(kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d)
echo "Username: ${ARGOCD_USER}"
echo "Password: ${ARGOCD_PWD}"
Username: admin
Password: 7kYgVfdcwv7aOo3s
혹은
export | grep ARGOCD_PWD
declare -x ARGOCD_PWD="BM4BevfR1u5GZHB3"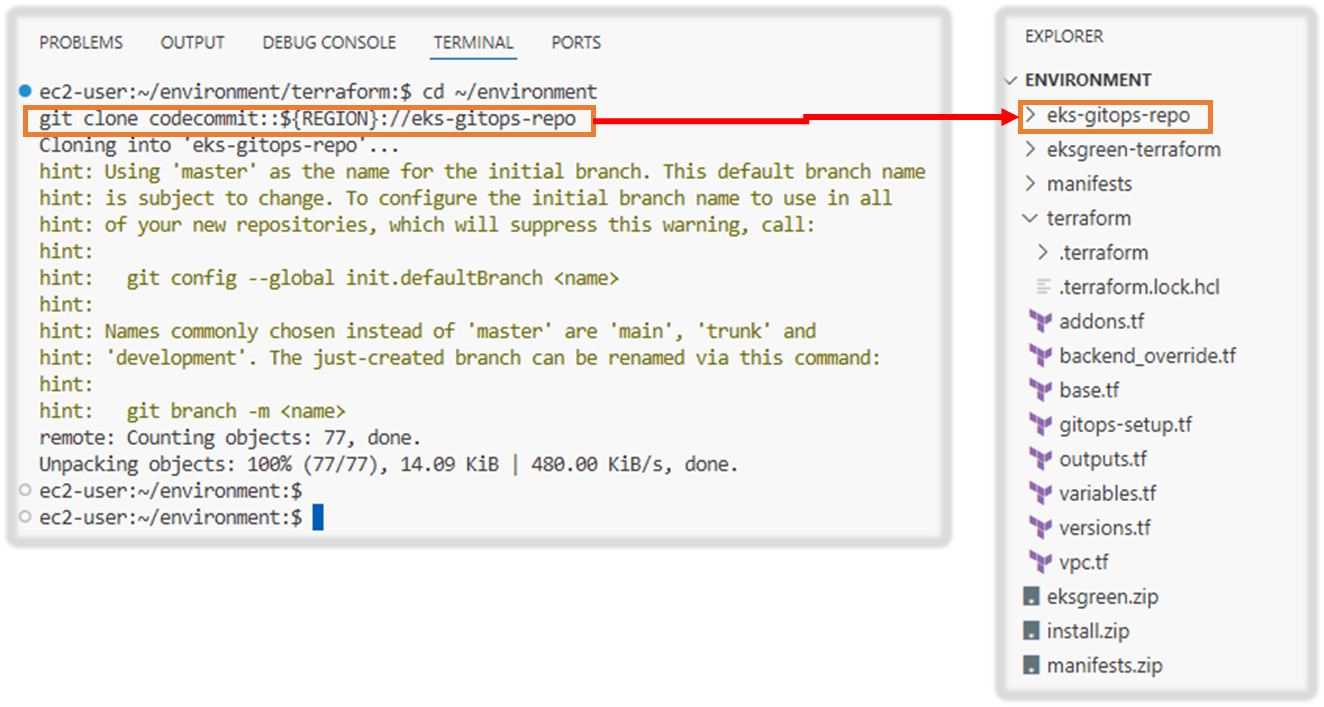

- Argo CD 웹 확인

- Argo CD CLI 확인
#
argocd login ${ARGOCD_SERVER} --username ${ARGOCD_USER} --password ${ARGOCD_PWD} --insecure --skip-test-tls --grpc-web
'admin:login' logged in successfully
Context 'k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com' updated
#
argocd repo list
TYPE NAME REPO INSECURE OCI LFS CREDS STATUS MESSAGE PROJECT
git https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo false false false true Successful
#
argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/apps https://kubernetes.default.svc default Synced Healthy Auto <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo app-of-apps
argocd/assets https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/assets main
argocd/carts https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/carts main
argocd/catalog https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/catalog main
argocd/checkout https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/checkout main
argocd/karpenter https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/karpenter main
argocd/orders https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/orders main
argocd/other https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/other main
argocd/rabbitmq https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/rabbitmq main
argocd/ui https://kubernetes.default.svc default OutOfSync Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/ui main
argocd app get apps
Name: argocd/apps
Project: default
Server: https://kubernetes.default.svc
Namespace:
URL: https://k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com/applications/apps
Source:
- Repo: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
Target:
Path: app-of-apps
SyncWindow: Sync Allowed
Sync Policy: Automated
Sync Status: Synced to (acc257a)
Health Status: Healthy
GROUP KIND NAMESPACE NAME STATUS HEALTH HOOK MESSAGE
argoproj.io Application argocd karpenter Synced application.argoproj.io/karpenter created
argoproj.io Application argocd carts Synced application.argoproj.io/carts created
argoproj.io Application argocd assets Synced application.argoproj.io/assets created
argoproj.io Application argocd catalog Synced application.argoproj.io/catalog created
argoproj.io Application argocd checkout Synced application.argoproj.io/checkout created
argoproj.io Application argocd rabbitmq Synced application.argoproj.io/rabbitmq created
argoproj.io Application argocd other Synced application.argoproj.io/other created
argoproj.io Application argocd ui Synced application.argoproj.io/ui created
argoproj.io Application argocd orders Synced application.argoproj.io/orders created
argocd app get carts
Name: argocd/carts
Project: default
Server: https://kubernetes.default.svc
Namespace:
URL: https://k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com/applications/carts
Source:
- Repo: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
Target: main
Path: apps/carts
SyncWindow: Sync Allowed
Sync Policy: Automated (Prune)
Sync Status: Synced to main (acc257a)
Health Status: Healthy
GROUP KIND NAMESPACE NAME STATUS HEALTH HOOK MESSAGE
Namespace carts Synced namespace/carts created
ServiceAccount carts carts Synced serviceaccount/carts created
ConfigMap carts carts Synced configmap/carts created
Service carts carts-dynamodb Synced Healthy service/carts-dynamodb created
Service carts carts Synced Healthy service/carts created
apps Deployment carts carts Synced Healthy deployment.apps/carts created
apps Deployment carts carts-dynamodb Synced Healthy deployment.apps/carts-dynamodb created
#
argocd app get carts -o yaml
...
spec:
destination:
server: https://kubernetes.default.svc
ignoreDifferences:
- group: apps
jsonPointers:
- /spec/replicas
- /metadata/annotations/deployment.kubernetes.io/revision
kind: Deployment
- group: autoscaling
jsonPointers:
- /status
kind: HorizontalPodAutoscaler
project: default
source:
path: apps/carts
repoURL: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- RespectIgnoreDifferences=true
...
argocd app get ui -o yaml
...
spec:
destination:
server: https://kubernetes.default.svc
ignoreDifferences:
- group: apps
jsonPointers:
- /spec/replicas
- /metadata/annotations/deployment.kubernetes.io/revision
kind: Deployment
- group: autoscaling
jsonPointers:
- /status
kind: HorizontalPodAutoscaler
project: default
source:
path: apps/ui
repoURL: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- RespectIgnoreDifferences=true
...
▶ (추가) UI 접속을 위한 NLB 설정
#
cat << EOF > ~/environment/eks-gitops-repo/apps/ui/service-nlb.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-type: external
labels:
app.kubernetes.io/instance: ui
app.kubernetes.io/name: ui
name: ui-nlb
namespace: ui
spec:
type: LoadBalancer
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/instance: ui
app.kubernetes.io/name: ui
EOF
cat << EOF > ~/environment/eks-gitops-repo/apps/ui/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: ui
resources:
- namespace.yaml
- configMap.yaml
- serviceAccount.yaml
- service.yaml
- deployment.yaml
- hpa.yaml
- service-nlb.yaml
EOF
#
cd ~/environment/eks-gitops-repo/
git add apps/ui/service-nlb.yaml apps/ui/kustomization.yaml
git commit -m "Add to ui nlb"
git push
argocd app sync ui
...
#
# UI 접속 URL 확인 (1.5, 1.3 배율)
kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "UI URL = http://"$1""}'

▶ [옵션] AWS CLI 자격증명 확인 - 제공된 IDE 환경에서만 정상적인 자격증명 동작함!!

# IDE-Server
aws sts get-caller-identity
{
"UserId": "AROAVJNSDOMR55BSJL27Y:i-00d9a1ac022bd4f29",
"Account": "363835126563",
"Arn": "arn:aws:sts::363835126563:assumed-role/workshop-stack-IdeIdeRoleD654ADD4-nSApoLMDr5GW/i-00d9a1ac022bd4f29"
}
aws s3 ls
2025-03-28 11:56:25 workshop-stack-tfstatebackendbucketf0fc9a9d-2phddn8usnlw
# 자신의 PC에서 aws cli 자격증명 사용 시
aws sts get-caller-identity
{
"UserId": "AROAVJNSDOMR7XPF3SIBJ:Participant",
"Account": "363835126563",
"Arn": "arn:aws:sts::363835126563:assumed-role/WSParticipantRole/Participant"
}
aws s3 ls
An error occurred (AccessDenied) when calling the ListBuckets operation: User: arn:aws:sts::363835126563:assumed-role/WSParticipantRole/Participant is not authorized to perform: s3:ListAllMyBuckets because no identity-based policy allows the s3:ListAllMyBuckets action
eksctl get cluster
NAME REGION EKSCTL CREATED
eksworkshop-eksctl us-west-2 False3-2. Introduction
▶ K8S(+AWS EKS) Release Cycles
쿠버네티스 프로젝트는 새로운 기능, 최신 보안 패치 및 버그 수정으로 지속적으로 업데이트됩니다. 쿠버네티스 버전 의미론을 처음 접하는 경우 의미론적 버전 관리를 따릅니다. 용어이며 일반적으로 xyz 로 표현되며 , 여기서 x 는 주요 버전이고, y 는 부차 버전이고, z는 패치 버전입니다. 새로운 Kubernetes 부차 버전( y )은 대략 4개월마다 출시되며, 모든 버전 >=v1.19에는 12개월 동안 표준 지원이 제공됩니다. 한 번에 최소 3개의 부차 버전에 대한 표준 지원이 제공됩니다. Kubernetes 프로젝트는 가장 최근의 3개 부차 릴리스에 대한 릴리스 브랜치를 유지 관리하며, 최신 Kubernetes 릴리스와 관련된 자세한 내용은 여기에서 확인할 수 있습니다. .

Amazon EKS 출시 일정 및 지원
Amazon Elastic Kubernetes Service(EKS)는 Kubernetes 프로젝트 릴리스 주기를 따르지만, 한 번에 4개의 마이너 버전에 대한 표준 지원을 제공하며, Amazon EKS에서 버전이 처음 제공된 후 14개월 동안 지속됩니다. 이는 업스트림 Kubernetes가 Amazon EKS에서 제공되는 버전을 더 이상 지원하지 않는 경우에도 마찬가지입니다. Amazon EKS에서 지원되는 Kubernetes 버전에 적용되는 보안 패치를 백포트합니다.
Amazon EKS Kubernetes 출시 일정 Amazon EKS에서 지원되는 각 Kubernetes 버전에 대한 중요한 릴리스 및 지원 날짜가 있습니다. 최신 EKS 버전의 릴리스가 Kubernetes의 해당 버전보다 몇 주 정도 뒤처지는 이유가 궁금하다면, Amazon이 Kubernetes의 새 버전이 Amazon EKS에서 제공되기 전에 다른 AWS 서비스 및 도구와의 안정성과 호환성을 철저히 테스트하기 때문입니다. 새 버전이 얼마나 빨리 지원될지에 대한 구체적인 날짜나 SLA는 제공하지 않지만, Amazon EKS 팀은 업스트림 릴리스와 EKS에 제공되는 지원 간의 격차를 메우기 위해 노력하고 있습니다.
Amazon EKS는 표준 지원 외에도 최근 확장 지원 기능을 출시했습니다( 출시 발표) ). 모든 Kubernetes 버전 1.21 이상은 이제 Amazon EKS에서 확장 지원을 받을 수 있습니다. 확장 지원은 표준 지원이 종료된 직후 자동으로 시작되어 12개월 더 지속되어 각 Kubernetes 마이너 버전에 대한 지원이 총 26개월로 늘어납니다. 클러스터가 확장 지원 기간이 끝나기 전에 업데이트되지 않으면 현재 지원되는 가장 오래된 확장 버전으로 자동 업그레이드됩니다. 자세한 내용은 Kubernetes 버전에 대한 Amazon EKS 확장 지원을 참조하세요.
확장 지원 기간 동안 Kubernetes 버전을 실행하는 클러스터의 가격은 2024년 4월 1일부터 클러스터당 시간당 총 $0.60으로 청구되는 반면, 표준 지원 비용(클러스터당 시간당 $0.10)은 변경되지 않습니다.

2024년 7월 23일 Amazon EKS는 Kubernetes 버전 정책( 출시 발표) 을 발표했습니다. ). Kubernetes 버전 정책에 대한 Amazon EKS 제어를 통해 클러스터 관리자는 EKS 클러스터에 대한 표준 지원 종료 동작을 선택할 수 있습니다. 이러한 제어를 통해 Kubernetes 버전에 대한 표준 지원 종료 시 확장 지원에 들어갈 클러스터와 자동으로 업그레이드될 클러스터를 결정할 수 있습니다. 이 제어는 클러스터당 실행되는 환경 또는 애플리케이션에 따라 버전 업그레이드와 비즈니스 요구 사항 간의 균형을 맞출 수 있는 유연성을 제공합니다.
속성을 사용하여 새 클러스터와 기존 클러스터 모두에 대한 버전 정책을 설정할 수 있습니다 supportType. 버전 지원 정책을 설정하는 데 사용할 수 있는 두 가지 옵션이 있습니다.
STANDARD— 표준 지원 종료 시 자동 업그레이드가 가능한 EKS 클러스터. 이 설정에서는 확장 지원 요금이 발생하지 않지만 EKS 클러스터는 표준 지원에서 지원되는 다음 Kubernetes 버전으로 자동 업그레이드됩니다.
EXTENDED— Kubernetes 버전이 표준 지원 종료에 도달하면 EKS 클러스터가 확장 지원으로 전환됩니다. 이 설정으로 확장 지원 요금이 부과됩니다. 클러스터를 표준 지원 Kubernetes 버전으로 업그레이드하면 확장 지원 요금이 부과되지 않습니다. 확장 지원으로 실행되는 클러스터는 확장 지원 종료 시 자동 업그레이드 대상이 됩니다.
이 동작은 EKS 콘솔 및 CLI를 통해 쉽게 설정할 수 있습니다. 자세한 내용은 클러스터 업그레이드 정책을 참조하세요.
▶ 왜 업그레이드를 해야 하나요?
컨테이너 관리 플랫폼으로 Kubernetes 또는 Amazon Elastic Kubernetes Service(EKS)를 선택할 때 고려해야 할 핵심 사항 중 하나는 정기적인 클러스터 업그레이드를 계획하고 커밋하는 것입니다. Amazon EKS 버전을 업데이트하는 것은 Kubernetes 클러스터의 보안, 안정성, 성능 및 호환성을 유지하는 데 중요하며, 플랫폼에서 제공하는 최신 기능과 역량을 활용할 수 있도록 보장합니다.
[ 공동 책임 모델 ]
- 참고 : https://catalog.us-east-1.prod.workshops.aws/event/dashboard/en-US/workshop/introduction/why-upgrade
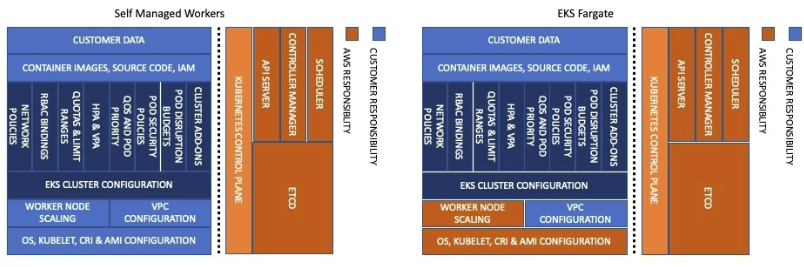

Kubernetes 버전은 제어 평면과 데이터 평면을 모두 포함합니다. AWS가 제어 평면을 관리하고 업그레이드하는 동안, 귀하(클러스터 소유자/고객)는 클러스터 제어 평면과 데이터 평면 모두에 대한 업그레이드를 시작할 책임이 있습니다. 클러스터 업그레이드를 시작하면 AWS가 제어 평면을 업그레이드하고 귀하는 여전히 데이터 평면의 업그레이드를 시작할 책임이 있습니다. 여기에는 Self Managed 노드 그룹, Managed 노드 그룹, Fargate 및 기타 애드온을 통해 프로비저닝된 작업자 노드가 포함됩니다. . 작업자 노드가 Karpenter Controller를 통해 프로비저닝되는 경우 Drift 를 활용할 수 있습니다. 또는 Disruption Controller 자동 노드 재활용 및 업그레이드를 위한 기능( spec.expireAfter). 클러스터 업그레이드를 계획할 때 워크로드의 애플리케이션 가용성을 보장하고 적절한 PodDisruptionBudgets를 확보해야 합니다. 그리고 토폴로지 스프레드 제약 조건 데이터 플레인이 업그레이드되는 동안 워크로드의 가용성을 보장하는 것이 중요합니다.
Amazon EKS는 Kubernetes 부 버전 외에도 새로운 Kubernetes 제어 평면 설정을 활성화하고 보안 수정 사항을 제공하기 위해 주기적으로 새로운 플랫폼 버전을 출시합니다. 각 Amazon EKS 부 버전은 하나 이상의 연관된 플랫폼 버전을 가질 수 있습니다. Amazon EKS에서 1.30과 같은 새로운 Kubernetes 부 버전이 제공되는 경우 해당 Kubernetes 부 버전의 초기 플랫폼 버전은 eks.1에서 시작하고 새로운 릴리스가 있을 때마다 플랫폼 버전이 증가합니다( ). 아래 표는 이를 더 잘 시각화하는 데 도움이 되며 Amazon EKS 플랫폼 버전eks.n+1 에서 자세한 내용을 찾을 수 있습니다. 좋은 소식은 Amazon EKS가 모든 기존 클러스터를 해당 Kubernetes 마이너 버전에 맞는 최신 Amazon EKS 플랫폼 버전으로 자동 업그레이드하므로 사용자 측에서 명시적으로 조치를 취할 필요가 없다는 것입니다.

따라서 Kubernetes 업데이트 관점에서 최신 마이너 버전 을 유지하는 것은 안전하고 효율적인 EKS 환경에 가장 중요하며, 이는 Amazon EKS의 공유 책임 모델을 반영합니다. 클러스터가 최신 보안 패치와 버그 수정을 실행하고 있는지 확인하여 보안 취약성의 위험을 줄입니다. 또한 향상된 성능, 확장성 및 안정성을 제공하여 애플리케이션과 고객에게 더 나은 서비스를 제공합니다.
▶ Amazon EKS 업그레이드
이 워크숍을 진행하면서 인플레이스 클러스터 업그레이드 및 블루그린 업그레이드와 같은 다양한 업그레이드 전략에 대해 알아봅니다. 또한 업그레이드 전략을 결정하는 기준과 이러한 각 전략을 수행하는 방법에 대한 자세한 단계에 대해서도 알아봅니다.
아래는 기존 클러스터 업그레이드의 높은 수준의 워크플로우입니다. 다음 모듈에서 이에 대해 더 자세히 살펴보겠습니다.

Amazon EKS 클러스터의 기존 업그레이드를 수행하려면 아래 작업을 수행해야 합니다.
- Kubernetes 및 EKS 릴리스 노트를 검토하세요. . 또한 업그레이드하기 전에 확인하세요 업그레이드를 시작하기 전에 구현해야 할 중요한 정책, 도구 및 절차를 검토하는 섹션입니다.
- 클러스터 백업을 수행합니다. (선택 사항)
- AWS 콘솔이나 CLI를 사용하여 클러스터 제어 평면을 업그레이드합니다.
- 추가 기능 호환성을 검토하세요.
- 클러스터 데이터 플레인을 업그레이드합니다.
위의 단계는 높은 수준의 시퀀스만을 나타내며, API 지원 중단/해결, 버전 불균형 검사 등 다른 검사가 있을 수 있습니다. 자세한 내용은 여기에서 확인할 수 있습니다. 또한 클러스터 업그레이드를 참조하세요. Amazon EKS 클러스터 업그레이드와 관련된 모범 사례 및 지침은 EKS 모범 사례 가이드 섹션을 참조하세요.
이제 다음 섹션에서 EKS 클러스터 업그레이드를 준비하는 과정을 시작해 보겠습니다.
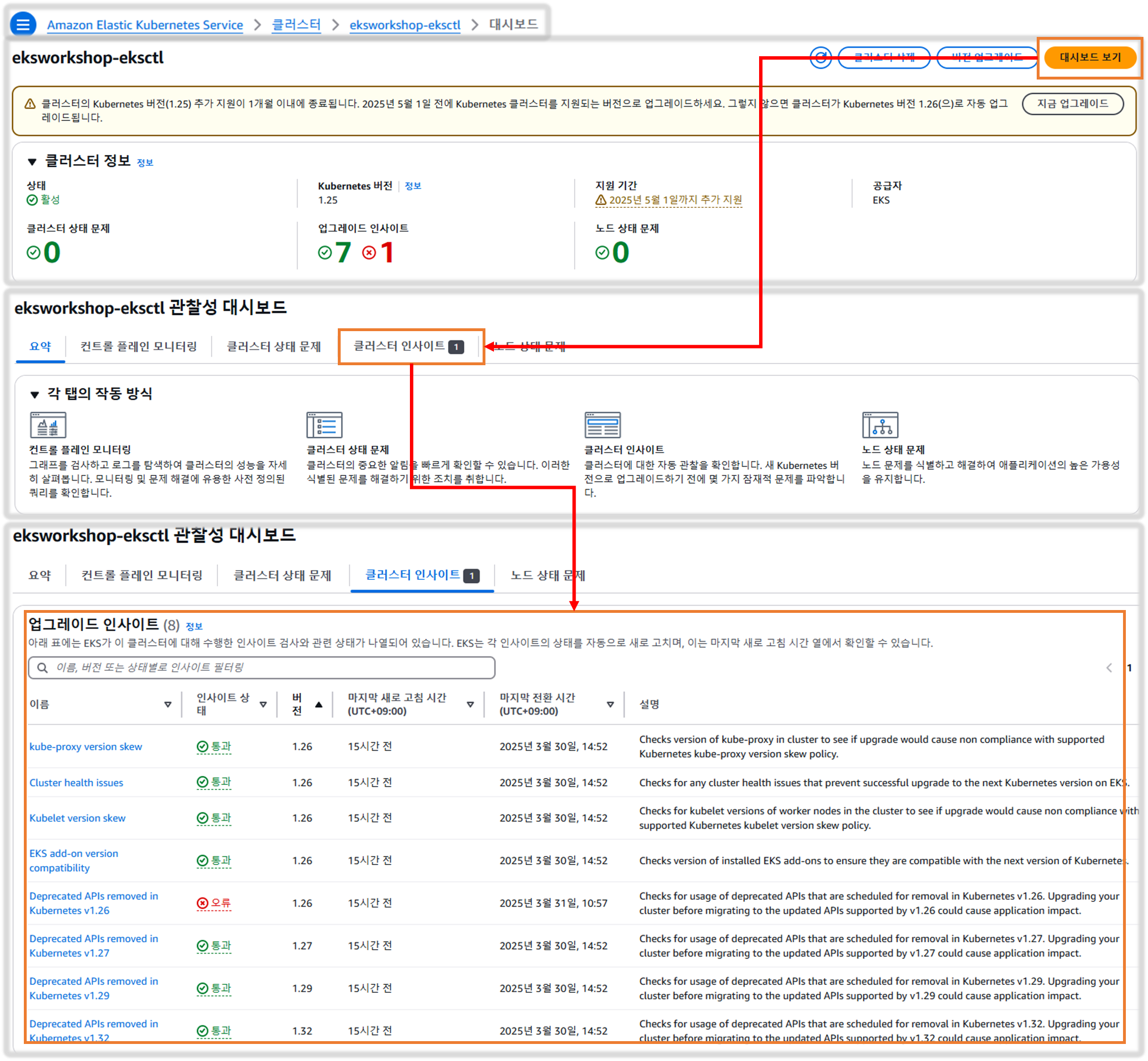
3-3. Preparing for Cluster Upgrades
▶ EKS 업그레이드 인사이트
EKS 업그레이드 인사이트
aws eks list-insights --filter kubernetesVersions=1.26 --cluster-name $CLUSTER_NAME | jq .Amazon EKS 클러스터 인사이트는 Amazon EKS 및 Kubernetes 모범 사례를 따르는 데 도움이 되는 권장 사항을 제공합니다. 모든 Amazon EKS 클러스터는 Amazon EKS에서 큐레이팅한 인사이트 목록에 대해 자동으로 반복되는 검사를 거칩니다. 이러한 인사이트 검사는 Amazon EKS에서 완전히 관리하며 발견 사항을 해결하는 방법에 대한 권장 사항을 제공합니다. Cluster Insights를 활용하면 최신 Kubernetes 버전으로 업그레이드하는 데 드는 노력을 최소화할 수 있습니다.
Amazon EKS 업그레이드 인사이트로 Kubernetes 업그레이드 간소화
Amazon EKS가 제어 평면 업그레이드를 자동화하는 반면, 업그레이드로 인해 영향을 받을 가능성이 있는 리소스나 애플리케이션을 식별하는 것은 수동 프로세스였습니다. 여기에는 릴리스 노트를 검토하여 더 이상 사용되지 않거나 제거된 Kubernetes API를 확인한 다음 해당 API를 사용하는 애플리케이션을 검색하여 수정하는 작업이 포함됩니다.
구조에 대한 통찰력을 업그레이드하세요
Amazon EKS 업그레이드 인사이트는 이러한 과제를 해결합니다. 매일 클러스터 감사 로그를 스캔하여 사용되지 않는 리소스를 찾고 EKS 콘솔에 결과를 표시하거나 API 또는 CLI를 통해 프로그래밍 방식으로 검색할 수 있습니다.
현재 Amazon EKS는 Kubernetes 버전 업그레이드 준비와 관련된 통찰력만 반환합니다.
참고: 클러스터 인사이트는 주기적으로 업데이트됩니다. 클러스터 인사이트를 수동으로 새로 고칠 수 없습니다. 클러스터 문제를 해결하면 클러스터 인사이트가 업데이트되는 데 시간이 걸립니다.
각 통찰력에는 다음이 포함됩니다.
- 권장 사항: 문제를 해결하기 위한 단계.
- 링크: 릴리스 노트, 블로그 게시물과 같은 추가 정보입니다.
- 리소스 목록: 심각도를 반영하는 상태(통과, 경고, 오류, 알 수 없음)가 있는 Kubernetes 리소스 유형(예: CronJobs)입니다.
- 오류: 다음 마이너 버전에서 API에 대한 호출이 제거되었습니다. 업그레이드 후 업그레이드가 실패합니다.
- 경고: 임박한 문제이지만 즉각적인 조치가 필요하지 않습니다(2개 이상 릴리스된 버전에서 지원 중단).
- 알 수 없음: 백엔드 처리 오류.
- 전체 상태: 인사이트의 모든 리소스 중에서 가장 높은 심각도 상태입니다. 이를 통해 업그레이드하기 전에 클러스터에 수정이 필요한지 빠르게 확인할 수 있습니다.
Amazon EKS 클러스터를 버전 1.25에서 1.26으로 업그레이드하는 방법을 알아보겠습니다. 대상 버전인 1.26과 관련된 클러스터 인사이트를 가져오는 것으로 시작하겠습니다.
EKS 클러스터의 통찰력을 보려면 다음 명령을 실행할 수 있습니다.
aws eks list-insights --filter kubernetesVersions=1.26 --cluster-name $CLUSTER_NAME | jq .Output :
{
"insights": [
{
"id": "4c7c2fc1-253d-463f-b2c4-2d302ccc4a10",
"name": "Deprecated APIs removed in Kubernetes v1.26",
"category": "UPGRADE_READINESS",
"kubernetesVersion": "1.26",
"lastRefreshTime": "2024-05-16T10:07:51+00:00",
"lastTransitionTime": "2024-05-13T21:52:45+00:00",
"description": "Checks for usage of deprecated APIs that are scheduled for removal in Kubernetes v1.26. Upgrading your cluster before migrating to the updated APIs supported by v1.26 could cause application impact.",
"insightStatus": {
"status": "PASSING",
"reason": "No deprecated API usage detected within the last 30 days."
}
}
]
}수신된 통찰력에 대한 보다 자세한 설명적 출력을 위해 다음과 같이 --id 플래그를 특정 통찰력 ID로 바꿔서 describe-insight 명령을 실행할 수 있습니다.
{
"insight": {
"id": "4c7c2fc1-253d-463f-b2c4-2d302ccc4a10",
"name": "Deprecated APIs removed in Kubernetes v1.26",
"category": "UPGRADE_READINESS",
"kubernetesVersion": "1.26",
"lastRefreshTime": "2024-05-16T10:07:51+00:00",
"lastTransitionTime": "2024-05-13T21:52:45+00:00",
"description": "Checks for usage of deprecated APIs that are scheduled for removal in Kubernetes v1.26. Upgrading your cluster before migrating to the updated APIs supported by v1.26 could cause application impact.",
"insightStatus": {
"status": "PASSING",
"reason": "No deprecated API usage detected within the last 30 days."
},
"recommendation": "Update manifests and API clients to use newer Kubernetes APIs if applicable before upgrading to Kubernetes v1.26.",
"additionalInfo": {
"EKS update cluster documentation": "https://docs.aws.amazon.com/eks/latest/userguide/update-cluster.html",
"Kubernetes v1.26 deprecation guide": "https://kubernetes.io/docs/reference/using-api/deprecation-guide/#v1-26"
},
"resources": [],
"categorySpecificSummary": {
"deprecationDetails": [
{
"usage": "/apis/flowcontrol.apiserver.k8s.io/v1beta1/flowschemas",
"replacedWith": "/apis/flowcontrol.apiserver.k8s.io/v1beta3/flowschemas",
"stopServingVersion": "1.26",
"startServingReplacementVersion": "1.26",
"clientStats": []
},
{
"usage": "/apis/flowcontrol.apiserver.k8s.io/v1beta1/prioritylevelconfigurations",
"replacedWith": "/apis/flowcontrol.apiserver.k8s.io/v1beta3/prioritylevelconfigurations",
"stopServingVersion": "1.26",
"startServingReplacementVersion": "1.26",
"clientStats": []
},
{
"usage": "/apis/autoscaling/v2beta2/horizontalpodautoscalers",
"replacedWith": "/apis/autoscaling/v2/horizontalpodautoscalers",
"stopServingVersion": "1.26",
"startServingReplacementVersion": "1.23",
"clientStats": []
}
]
}
}
}
이 정보는 Amazon EKS 콘솔 업그레이드 인사이트 탭에서도 얻을 수 있습니다. EKS AWS 콘솔에서 업그레이드 인사이트로 이동하는 방법은 다음과 같습니다.
- Amazon EKS 콘솔을 엽니다: https://console.aws.amazon.com/eks/home
- 클러스터 목록에서 통찰력을 보고 싶은 특정 Amazon EKS 클러스터의 이름을 선택합니다.
- 업그레이드 인사이트 탭을 클릭하세요.
업그레이드 인사이트 페이지에는 클러스터 환경에서 감지된 잠재적인 업그레이드 준비 문제에 대한 정보가 표시됩니다. 이 정보는 EKS에서 지원하는 향후 Kubernetes 버전으로의 업그레이드를 계획하고 실행하는 데 유용합니다.

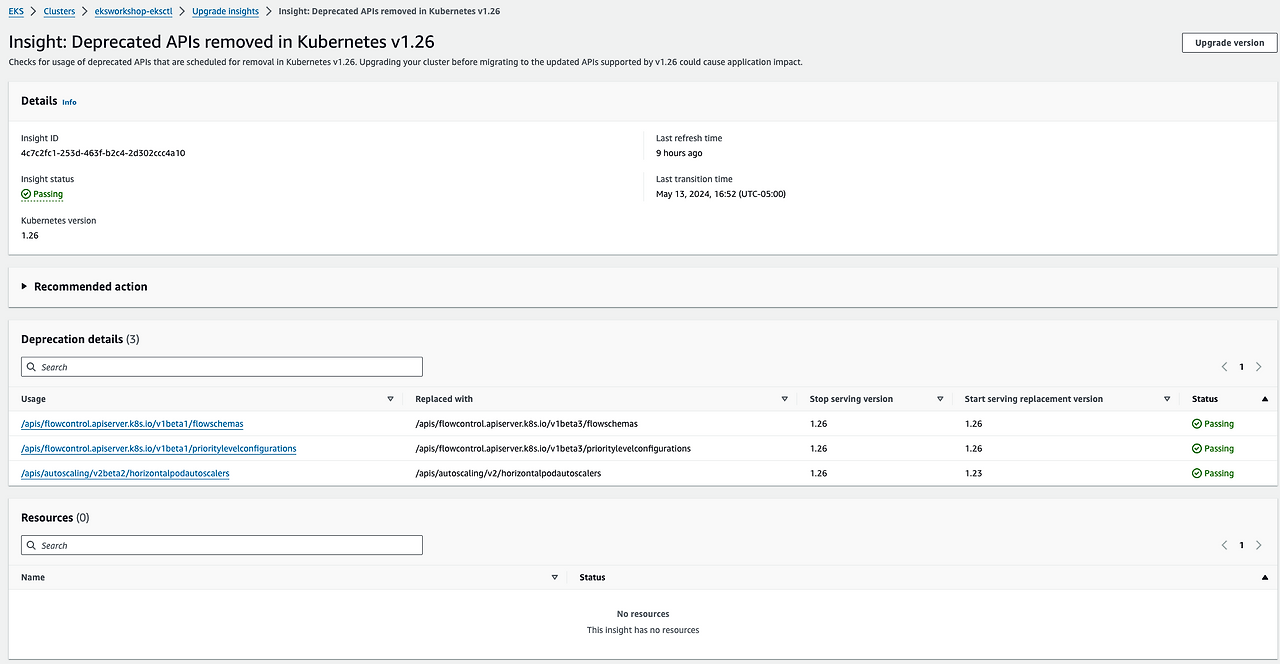
참고: 현재 v1.25에서 v1.26으로 업그레이드하는 시나리오에서는 ERROR 또는 WARNING 메시지가 나타나지 않습니다. 그러나 이는 클러스터마다 다를 수 있습니다.
설명 시나리오:
다음은 업그레이드 인사이트 탭에서 API 상태가 ERROR로 표시되는 예이며, 이는 해당 API가 v1.25에서 지원 중단될 예정임을 나타냅니다.
이 API 지원 중단에 대한 자세한 정보를 보려면 인사이트 이름을 클릭하세요.

이 이미지에서 우리는 업그레이드 인사이트가 Kubernetes 버전 1.25로 업그레이드할 때 지원 중단으로 인해 API를 활용하는 클러스터에서 실행 중인 리소스 유형을 식별하는 데 도움이 된다는 것을 알 수 있습니다.
리소스 유형은 동일하지만 API 버전을 업데이트해야 하는 경우 kubectl-convert 명령을 사용하여 매니페스트 파일을 자동으로 변환할 수 있습니다.
kubectl-convert: 매니페스트 마이그레이션을 위한 도구
kubectl-convert는 Kubernetes 매니페스트를 최신 API 버전에서 작동하도록 마이그레이션하는 데 편리한 유틸리티입니다. 이는 API가 최신 Kubernetes 릴리스에서 더 이상 사용되지 않거나 제거될 때 중요해집니다. 도움이 될 수 있습니다.
- API 버전 업데이트: 매니페스트가 더 이상 사용되지 않는 API(예: Ingress의 extensions/v1beta1)를 사용하는 경우 kubectl-convert가 이를 지원되는 버전(예: networking.k8s.io/v1)으로 업데이트할 수 있습니다.
- 호환성 보장: 매니페스트의 API 버전을 업데이트하면 kubectl-convert가 Kubernetes 클러스터 업그레이드 후에도 애플리케이션이 원활하게 작동하도록 보장합니다.
kubectl-convert는 플러그인입니다. 이전 버전의 kubectl에는 kubectl-convert가 내장되어 있었지만, 이제는 별도의 플러그인입니다. 사용하기 전에 설치해야 합니다( https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/#install-kubectl-convert-plugin ) ).
kubectl-convert 사용:
기본 사용법에는 매니페스트 파일과 원하는 출력 버전을 지정하는 것이 포함됩니다.
Memo :
kubectl convert -f <manifest_file> --output-version <api_group>/<version>
ex)
kubectl convert -f deployment.yaml --output-version apps/v1
이 명령은 apps/v1 API 버전을 사용하도록 deployment.yaml 파일을 업데이트합니다(이전 버전을 사용하고 있다고 가정).
Memorize !!
- kubectl-convert로 매니페스트를 업데이트한 후 kubectl apply를 사용하여 클러스터에 다시 적용해야 합니다.
- kubectl-convert를 사용하기 전에 원본 매니페스트를 백업하는 것이 좋습니다. kubectl-convert를 활용하여 매니페스트를 마이그레이션하면 새로운 Kubernetes 버전으로 원활하게 전환하고 애플리케이션 중단을 피할 수 있습니다.
▶ AWS EKS 업그레이드 체크리스트
EKS 문서를 사용하여 업그레이드 체크리스트를 만듭니다. EKS Kubernetes 버전 설명서에는 각 버전에 대한 자세한 변경 사항 목록이 포함되어 있습니다. 각 업그레이드에 대한 체크리스트를 작성하세요.
EKS 버전 업그레이드에 대한 구체적인 지침은 설명서를 참조하여 각 버전의 주요 변경 사항과 고려 사항을 확인하세요.
API를 사용하여 Kubernetes 애드온 및 구성 요소 업그레이드
Kubernetes 클러스터를 업그레이드하려면 다양한 구성 요소를 신중하게 고려해야 합니다.
- API 종속 구성 요소 식별: 업그레이드하기 전에 다음을 사용하여 모든 클러스터 구성 요소를 나열합니다.
kubectl get ns | grep -e '-system'
이를 통해 Kubernetes API와 직접 상호 작용하는 모니터링 에이전트, 자동 확장기 및 스토리지 드라이버와 같은 중요한 구성 요소를 정확히 찾는 데 도움이 됩니다.
- 호환성을 위해 설명서를 확인하세요:
식별된 각 구성 요소에 대해 해당 설명서를 참조하여 대상 Kubernetes 버전과의 호환성을 확인하세요. AWS Load Balancer Controller 설명서와 같은 리소스는 버전 호환성 세부 정보를 제공합니다. 일부 구성 요소는 진행하기 전에 업그레이드 또는 구성 변경이 필요할 수 있습니다. CoreDNS, kube-proxy, Container Network Interface(CNI) 플러그인 및 스토리지 드라이버와 같은 중요한 구성 요소에 세심한 주의를 기울이세요.
- 애드온 및 타사 도구 업그레이드:
많은 클러스터는 Kubernetes API를 활용하여 유입 제어, 지속적인 전달 및 모니터링과 같은 기능을 제공하는 애드온 및 타사 도구에 의존합니다. EKS 클러스터를 업그레이드하려면 호환성을 유지하기 위해 이러한 도구를 업그레이드해야 합니다.
일반적인 추가 기능과 업그레이드 리소스를 살펴보겠습니다.
- Amazon VPC CNI : Amazon EKS 추가 기능 배포에 대한 업그레이드는 한 번에 하나의 마이너 버전 업그레이드로 제한됩니다.
- kube-proxy : Kubernetes kube-proxy 자체 관리 애드온 업데이트 에서 업그레이드 지침을 찾으세요. .
- CoreDNS : CoreDNS 자체 관리 애드온 업데이트 에서 업그레이드 지침을 사용할 수 있습니다. .
- AWS 로드 밸런서 컨트롤러 : EKS 버전과의 호환성이 중요합니다. 설치 가이드 를 참조하세요. 자세한 내용은.
- Amazon EBS/EFS CSI 드라이버 : 설치 및 업그레이드 정보는 Amazon EKS 추가 기능으로 Amazon EBS CSI 드라이버 관리 에서 찾을 수 있습니다. 및 Amazon EFS CSI 드라이버 각기.
- Metrics Server : 자세한 내용은 GitHub의 metrics-server를 참조하세요. .
- 클러스터 자동 확장기 : 배포 정의 내에서 이미지 버전을 수정하여 업그레이드합니다. 스케줄러와의 긴밀한 결합을 감안할 때 클러스터 자동 확장기는 일반적으로 클러스터 자체와 함께 업그레이드해야 합니다. GitHub 릴리스를 참조하세요. Kubernetes 마이너 버전과 호환되는 최신 이미지를 찾으세요.
- Karpenter : 설치 및 업그레이드 지침은 Karpenter 설명서를 참조하세요. .
추가 팁:
클러스터 백업: 복원 목적으로 클러스터의 진실의 출처를 갖는 것이 좋습니다. velero 와 같은 백업 도구를 사용할 수 있습니다. 업그레이드 프로세스를 시작하기 전에 클러스터 데이터를 백업합니다. 이렇게 하면 예상치 못한 문제가 발생할 경우 롤백 옵션이 보장됩니다.
테스트: 프로덕션에 배포하기 전에 업그레이드된 환경을 철저히 테스트합니다.
이러한 단계를 따르고 제공된 리소스를 참조하면 애드온 및 타사 도구 호환성을 유지하면서 Kubernetes 구성 요소를 효과적으로 업그레이드할 수 있습니다.
업그레이드하기 전에 기본 EKS 요구 사항을 확인하세요
AWS는 업그레이드 프로세스를 완료하기 위해 계정의 특정 리소스를 요구합니다. 이러한 리소스가 없으면 클러스터를 업그레이드할 수 없습니다. 제어 평면 업그레이드에는 다음 리소스가 필요합니다.
사용 가능한 IP 주소 확인
Amazon EKS 클러스터를 업그레이드하려면 원래 클러스터 생성 시 지정한 서브넷 내에 최소 5개의 여유 IP 주소가 필요합니다. 서브넷에 충분한 여유 IP 주소가 있는지 확인하려면 아래와 같이 특정 명령을 실행할 수 있습니다.
aws ec2 describe-subnets --subnet-ids \
$(aws eks describe-cluster --name ${CLUSTER_NAME} \
--query 'cluster.resourcesVpcConfig.subnetIds' \
--output text) \
--query 'Subnets[*].[SubnetId,AvailabilityZone,AvailableIpAddressCount]' \
--output tableOutput :
----------------------------------------------------
| DescribeSubnets |
+---------------------------+--------------+-------+
| subnet-02d741b52a0f9eaca | us-west-2a | 4069 |
| subnet-0eec75c6dcd088a33 | us-west-2c | 4069 |
| subnet-08241dc67a9050655 | us-west-2b | 4070 |
+---------------------------+--------------+-------+
기존 서브넷에 충분한 사용 가능한 IP가 없는 경우 Amazon에서는 UpdateClusterConfiguration을 사용하는 것이 좋습니다. 업그레이드를 진행하기 전에 클러스터 구성을 새로운 서브넷으로 업데이트하기 위한 API입니다.
새로운 서브넷 요구 사항:
가용성 영역(AZ) : 새 서브넷은 클러스터 생성 중에 원래 선택한 동일한 AZ 집합 내에 있어야 합니다. VPC 멤버십 : 새 서브넷은 클러스터와 연결된 동일한 VPC에 속해야 합니다.
IP 풀 확장(선택 사항):
서브넷 업데이트 후에도 충분한 IP가 없다면 추가 CIDR 블록을 VPC에 연결하는 것을 고려하세요. 이렇게 하면 기본적으로 사용 가능한 IP 주소 풀이 늘어납니다. 할 수 있는 일은 다음과 같습니다.
- 개인 CIDR 블록 추가 : RFC 1918을 준수하여 새로운 개인 IP 범위를 도입하여 IP 풀을 확장할 수 있습니다.
- 새로운 CIDR 기반 서브넷 업데이트 : VPC 내에서 새로 구성된 CIDR 블록을 반영하도록 클러스터 서브넷을 업데이트합니다.
이러한 지침을 따르면 EKS 클러스터가 원활한 Kubernetes 버전 업그레이드를 수행하는 데 필요한 IP 리소스를 확보할 수 있습니다.
EKS IAM 역할 확인
IAM 역할을 사용할 수 있는지, 그리고 계정에 올바른 역할 가정 정책이 있는지 확인하려면 다음 명령을 실행할 수 있습니다.
ROLE_ARN=$(aws eks describe-cluster --name ${CLUSTER_NAME} \
--query 'cluster.roleArn' --output text)
aws iam get-role --role-name ${ROLE_ARN##*/} \
--query 'Role.AssumeRolePolicyDocument'Output :
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EKSClusterAssumeRole",
"Effect": "Allow",
"Principal": {
"Service": "eks.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}EKS 보안 그룹: 알아야 할 사항
클러스터를 만들면 Amazon EKS는 eks-cluster-sg-my-cluster-uniqueID라는 이름의 보안 그룹을 만듭니다. 이 보안 그룹에는 다음과 같은 기본 규칙이 있습니다.

Amazon EKS 보안 그룹: 연결 및 규칙
Amazon EKS가 보안 그룹을 활용하는 방식에 대한 세부 내용은 다음과 같습니다.
- 자동 태그 : EKS는 클러스터에 대해 만든 보안 그룹에 특정 태그를 주입합니다. 이러한 태그는 작동에 필수적이며 제거하면 다시 추가됩니다.
- 리소스 연결 : 이 보안 그룹은 여러 리소스에 자동으로 연결됩니다.
- 네트워크 인터페이스(ENI): 클러스터를 프로비저닝하면 2-4개의 ENI가 생성됩니다. 이러한 ENI는 EKS에서 생성한 보안 그룹과도 연관됩니다.
- 관리형 노드 그룹 ENI: 사용자가 생성하는 모든 관리형 노드 그룹의 ENI도 이 보안 그룹에 연결됩니다.
- 기본 보안 규칙 : 처음에 보안 그룹은 제한 없는 통신을 허용합니다.
- 인바운드 트래픽: 모든 트래픽은 클러스터 제어 평면과 노드 간에 자유롭게 흐를 수 있습니다.
- 아웃바운드 트래픽: 노드는 모든 목적지로 트래픽을 보낼 수 있습니다.
- 사용자 지정 보안 그룹(선택 사항) : 클러스터 생성 중에 선택적으로 자체 보안 그룹을 지정할 수 있습니다. 그렇게 하는 경우:
- ENI 연결: EKS는 이러한 사용자 정의 그룹을 클러스터의 ENI와 연결합니다.
- 노드 그룹 제한: 그러나 이러한 사용자 지정 그룹은 귀하가 만든 노드 그룹에는 적용되지 않습니다. 이러한 연결을 별도로 관리해야 합니다.
기본적으로 EKS는 광범위한 권한을 가진 기본 보안 그룹을 제공하지만, 사용자가 사용자 정의 그룹을 사용하여 더 엄격한 보안 정책을 구현할 수 있도록 합니다.

EKS 클러스터의 보안 강화
EKS 클러스터 내에서 트래픽 흐름을 제한하고 싶으신가요? 알아야 할 사항은 다음과 같습니다.
- 기본 규칙은 개방적입니다. 기본적으로 EKS는 클러스터 구성 요소 간의 무제한 통신을 허용합니다.
- 아웃바운드 트래픽 사용자 지정: 열려 있는 포트를 제한하려면 기본 아웃바운드 규칙을 제거하고 다음 최소 요구 사항을 구현합니다.
- 노드 간 통신: 노드 간 통신에 사용하는 모든 프로토콜과 포트에 대한 규칙을 정의합니다.
- 인바운드 규칙 지속성: EKS는 업데이트 중에 기본 인바운드 규칙을 제거한 후에 해당 규칙을 자동으로 다시 생성합니다.
추가 교통 고려 사항:
- 아웃바운드 인터넷 액세스(선택 사항) : 노드에 인터넷 액세스가 필요한 경우(예: EKS API 호출 또는 초기 등록) 특정 포트에 대한 아웃바운드 규칙을 구성합니다. 개인 클러스터의 경우 인터넷 액세스가 필요하지 않을 수 있습니다. 개인 클러스터 요구 사항을 참조하세요. 자세한 내용은.
- 컨테이너 이미지 액세스 : 노드는 이미지를 가져오기 위해 컨테이너 레지스트리(예: Amazon ECR 또는 DockerHub)에 액세스해야 합니다. 적절한 레지스트리 엔드포인트에 대한 규칙을 만듭니다. AWS IP 주소 범위 확인 관련 IP 범위에 대해서.
- IPv4/IPv6에 대한 별도 규칙 : VPC가 두 주소 패밀리를 모두 사용하는 경우 각각에 대해 별도의 규칙이 필요합니다.
테스트는 매우 중요합니다. 프로덕션 클러스터에 변경 사항을 배포하기 전에 모든 Pod를 철저히 테스트하여 새로운 보안 규칙에 따라 올바르게 작동하는지 확인하세요.

▶ EKS 클러스터 업그레이드 고가용성(HA) 전략
인플레이스 클러스터 업그레이드 대안으로 블루/그린 클러스터 평가
일부 사용자는 블루/그린 업그레이드 전략을 채택하는 것을 선호합니다. 이 접근 방식은 여러 가지 이점을 제공하지만 고려해야 할 몇 가지 단점도 포함합니다.
이익
- 여러 EKS 버전을 동시에 변경 가능(예: 1.23에서 1.25로)
- 이전 클러스터로 다시 전환 가능
- 최신 시스템(예: Terraform)으로 관리할 수 있는 새 클러스터를 만듭니다.
- 작업 부하를 개별적으로 마이그레이션할 수 있습니다.
단점
- 소비자 업데이트가 필요한 API 엔드포인트 및 OIDC 변경(예: kubectl 및 CI/CD)
- 마이그레이션 중에 2개의 클러스터를 병렬로 실행해야 하므로 비용이 많이 들고 지역 용량이 제한될 수 있습니다.
- 작업 부하가 서로 의존하여 함께 마이그레이션되는 경우 더 많은 조정이 필요합니다.
- 로드 밸런서와 외부 DNS는 여러 클러스터에 쉽게 확장될 수 없습니다.
이 전략은 실행 가능하지만, 인플레이스 업그레이드보다 비용이 많이 들고 조정 및 워크로드 마이그레이션에 더 많은 시간이 필요합니다. 어떤 상황에서는 필요할 수 있으므로 신중하게 계획해야 합니다.
높은 수준의 자동화와 GitOps와 같은 선언적 시스템을 사용하면 이 접근 방식을 구현하기가 더 쉬울 수 있습니다. 그러나 데이터가 백업되고 새 클러스터로 마이그레이션되도록 하기 위해 상태 저장 워크로드에 대한 추가 예방 조치를 취해야 합니다.
원활한 배포를 위한 패키징 애플리케이션 정의
옵션-1: Helm 차트
쿠버네티스는 현대 클라우드 네이티브 기업을 위한 사실상의 컨테이너 오케스트레이션 도구가 되었지만, 일부에게는 복잡한 도구이기 때문에 학습 곡선이 높습니다. 쿠버네티스에서 애플리케이션을 구성하고 배포하는 프로세스는 어려운 작업이 될 수 있습니다.
Helm은 Kubernetes 애플리케이션을 관리하는 데 도움이 되는 오픈소스 도구입니다. Helm Charts는 빠르고 쉽게 배포할 수 있는 사전 구성된 Kubernetes 리소스 패키지입니다. Helm과 Helm Charts의 도움으로 개발자는 Kubernetes 배포 프로세스를 간소화하고 애플리케이션을 빠르게 가동할 수 있습니다.
Helm 차트는 Kubernetes 애플리케이션을 표준화된 형식으로 패키징하고 배포하는 방법을 제공하여 다양한 환경에서 애플리케이션을 공유하고 배포하는 것을 더 쉽게 만듭니다. 차트는 공개 또는 비공개 차트 저장소를 통해 공유하거나 내부 사용을 위해 로컬에 저장할 수 있습니다.

옵션 2: GitOps
GitOps는 Git과 대상 환경(예: Kubernetes) 사이에서 GitOps 에이전트가 사용되는 최신 지속적 배포(CD) 모델로 작동합니다. GitOps는 또한 Git에서 발생하는 모든 변경 사항을 추적합니다.
이 워크숍에서 사용되는 Argo CD는 Git에서 애플리케이션을 배포하고, 애플리케이션의 수명 주기를 관리하고, 환경을 동기화 상태로 유지하는 데 도움이 되는 선언적 GitOps 기반의 지속적인 배포 도구입니다.
Helm이 차트를 애플리케이션을 관리하고 배포하는 데 중요한 요소로 생각하는 반면, ArgoCD와 같은 GitOps 도구는 Git을 단일 진실 소스로 사용하고 이를 중심으로 애플리케이션 구성과 매니페스트를 저장하고 추적하여 복잡한 배포를 보다 쉽게 만듭니다.
참고: 이 워크숍에서는 업그레이드 프로세스 동안 원활한 애플리케이션 출시를 위한 GitOps 도구로 ArgoCD를 활용합니다.
데이터 플레인이 업그레이드되는 동안 워크로드의 가용성을 보장하기 위해 PodDisruptionBudgets 및 TopologySpreadConstraints 구성
중요 서비스의 경우 워크로드에 적절한 PodDisruptionBudget(PDB) 가 있는지 확인하세요. 및 TopologySpreadConstraints 데이터 플레인 업그레이드 중에 가용성을 유지합니다. 다양한 워크로드에는 다양한 가용성 요구 사항이 있으므로 각 워크로드의 규모와 요구 사항을 검증하는 것이 중요합니다.
토폴로지가 분산된 여러 가용성 영역과 호스트에 워크로드를 분산하면 워크로드가 자동으로 새로운 데이터 평면으로 문제 없이 마이그레이션될 것이라는 확신이 커집니다.
아래 PDB는 자발적 중단 중에 배포에서 적어도 하나의 포드가 orders사용 가능한 상태로 유지되도록 보장합니다. 더 높은 가용성을 보장해야 하는 경우 minAvailable 값을 적절히 조정할 수 있습니다. 이것을 GitOps 리포에 추가하고 변경 사항을 EKS 클러스터에 동기화해 보겠습니다.
cat << EOF > ~/environment/eks-gitops-repo/apps/orders/pdb.yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: orders-pdb
namespace: orders
spec:
minAvailable: 1
selector:
matchLabels:
app.kubernetes.io/component: service
app.kubernetes.io/instance: orders
app.kubernetes.io/name: orders
EOFkustomization.yaml이 리소스를 추가하고 CodeCommit repo에 변경 사항을 커밋하려면 를 업데이트합니다 .
echo " - pdb.yaml" >> ~/environment/eks-gitops-repo/apps/orders/kustomization.yaml
cd ~/environment/eks-gitops-repo/
git add apps/orders/kustomization.yaml
git add apps/orders/pdb.yaml
git commit -m "Add PDB to orders"
git push마지막으로 ArgoCD UI나 아래 명령을 사용하여 argocd 애플리케이션을 동기화합니다.
argocd app sync orders...
Operation: Sync
Sync Revision: f440f41a03c8a498162c4822109be106b7f39626
Phase: Succeeded
Start: 2024-08-30 16:10:50 +0000 UTC
Finished: 2024-08-30 16:10:53 +0000 UTC
Duration: 3s
Message: successfully synced (all tasks run)
...
3-4. Choosing an Upgrade Strategy : In-Place vs. Blue-Green
▶인플레이스 업그레이드 전략
인플레이스 업그레이드는 새 클러스터를 만들지 않고 기존 EKS 클러스터를 최신 Kubernetes 버전으로 업그레이드하는 전략입니다. 이 접근 방식은 동일한 클러스터 내에서 제어 플레인 및 데이터 플레인 구성 요소를 업데이트하므로 다운타임을 최소화하고 원활한 전환을 보장하기 위해 신중한 계획과 조정이 필요합니다.
내부 업그레이드 프로세스에는 일반적으로 다음 단계가 포함됩니다.
- EKS 제어 평면을 대상 Kubernetes 버전으로 업그레이드합니다.
- 새로운 Kubernetes 버전과 일치하도록 작업자 노드 AMI를 업데이트합니다.
- 애플리케이션 가동 중지 시간을 최소화하기 위해 작업자 노드를 한 번에 하나씩 또는 소규모로 비우고 교체합니다.
- 새 버전과의 호환성을 보장하기 위해 모든 Kubernetes 매니페스트, 애드온 및 구성을 업데이트합니다.
- 철저한 테스트와 검증을 수행하여 애플리케이션과 서비스가 예상대로 작동하는지 확인합니다.
인플레이스 업그레이드의 장점
- VPC, 서브넷, 보안 그룹 등 기존 클러스터 리소스와 구성을 유지합니다.
- 동일한 클러스터 API 엔드포인트를 유지하므로 외부 통합 및 도구를 업데이트할 필요성이 최소화됩니다.
- 업그레이드 프로세스 중에 여러 클러스터를 관리하는 것에 비해 인프라 오버헤드가 덜 필요합니다.
- 클러스터 간에 상태 저장 애플리케이션과 지속형 데이터를 마이그레이션할 필요성을 최소화합니다.
인플레이스 업그레이드의 단점
- 업그레이드 과정에서 가동 중지 시간을 최소화하려면 신중한 계획과 조정이 필요합니다.
- 여러 Kubernetes 버전을 건너뛸 경우 연속적인 업그레이드가 여러 번 필요할 수 있으며, 업그레이드 프로세스가 길어질 수 있습니다.
- 업그레이드 중에 문제가 발생하면 롤백이 더 어렵고 시간이 많이 걸릴 수 있습니다. Control Plane이 업그레이드되면 롤백할 수 없습니다.
- 호환성을 보장하기 위해 모든 구성 요소와 종속성에 대한 철저한 테스트와 검증이 필요합니다.
▶블루-그린 업그레이드 전략
Blue-Green 업그레이드는 대상 Kubernetes 버전으로 새 EKS 클러스터(녹색)를 만들고, 애플리케이션과 애드온을 새 클러스터에 배포하고, 트래픽을 이전 클러스터(파란색)에서 새 클러스터로 점진적으로 전환하는 전략입니다. 마이그레이션이 완료되면 이전 클러스터는 폐기됩니다. 이 접근 방식은 다운타임을 최소화하고 더 안전하고 제어된 업그레이드 프로세스를 제공합니다.
블루-그린 업그레이드 프로세스에는 일반적으로 다음 단계가 포함됩니다.
- 원하는 Kubernetes 버전 및 구성으로 새 EKS 클러스터(녹색)를 만듭니다.
- 새 클러스터에 애플리케이션, 애드온 및 구성을 배포합니다.
- 새 클러스터가 예상대로 작동하는지 확인하기 위해 철저한 테스트와 검증을 수행합니다.
- DNS 업데이트, 로드 밸런서 구성 또는 서비스 메시와 같은 기술을 사용하여 점진적으로 이전 클러스터(파란색)에서 새 클러스터(녹색)로 트래픽을 전환합니다.
- 새 클러스터를 면밀히 모니터링하여 트래픽을 처리하고 예상대로 성능이 발휘되는지 확인하세요.
- 모든 트래픽이 새 클러스터로 전환되면 이전 클러스터를 해제합니다.
블루-그린 업그레이드의 장점
- 새로운 클러스터를 프로덕션 트래픽으로 전환하기 전에 철저히 테스트할 수 있으므로, 보다 통제되고 안전한 업그레이드 프로세스가 가능합니다.
- 단일 업그레이드에서 여러 Kubernetes 버전을 건너뛸 수 있으므로 전체 업그레이드 시간과 노력이 줄어듭니다.
- 문제가 발생할 경우 트래픽을 이전 클러스터로 다시 전환하여 빠르고 쉬운 롤백 메커니즘을 제공합니다.
- 새 클러스터가 완전히 검증될 때까지 이전 클러스터가 계속 트래픽을 제공하므로 업그레이드 프로세스 동안 가동 중지 시간이 최소화됩니다.
블루-그린 업그레이드의 단점
- 두 개의 클러스터를 동시에 유지 관리해야 하므로 업그레이드 프로세스에 추가적인 인프라 리소스와 비용이 필요합니다.
- 클러스터 간 트래픽 이동에 대한 보다 복잡한 조정 및 관리가 필요합니다.
- CI/CD 파이프라인, 모니터링 시스템, 액세스 제어 등의 외부 통합을 업데이트하여 새 클러스터를 가리키도록 해야 합니다.
- 클러스터 간 데이터 마이그레이션이나 동기화가 필요한 상태 저장 애플리케이션의 경우 어려울 수 있습니다.
상태 저장 워크로드에 대한 고려 사항
상태 저장 워크로드에 대한 블루-그린 업그레이드를 수행할 때는 데이터 마이그레이션 및 동기화 프로세스를 신중하게 계획하고 실행하세요. Velero와 같은 도구를 사용하여 영구 데이터를 마이그레이션하고 클러스터 간에 데이터를 동기화 상태로 유지하며 빠른 롤백을 활성화하세요. 새 클러스터에서 영구 볼륨 프로비저닝을 구성하여 이전 클러스터의 스토리지 클래스 또는 프로비저너와 일치시키세요. 애플리케이션 설명서를 참조하고 애플리케이션 소유자와 협력하여 데이터 마이그레이션 및 동기화에 대한 특정 요구 사항을 이해하세요. Velero와 같은 도구를 적절히 계획하고 활용하는 것은 위험을 최소화하고 상태 저장 애플리케이션에 대한 원활한 업그레이드 프로세스를 보장하는 데 중요합니다.
▶In-Place와 Blue-Green 업그레이드 전략 중에서 선택
EKS 클러스터에 대한 내부 업그레이드와 Blue-Green 업그레이드를 선택할 때는 다양한 요소를 고려하고 특정 요구 사항과 제약 조건에 가장 적합한 접근 방식이 무엇인지 평가하는 것이 중요합니다.
전략을 선택할 때 고려해야 할 요소
- 가동 중지 허용 범위 : 업그레이드 프로세스 중에 애플리케이션과 서비스에 대한 허용 가능한 가동 중지 시간 수준을 고려하세요.
- 복잡성 업그레이드 : 애플리케이션 아키텍처, 종속성 및 상태 구성 요소의 복잡성을 평가합니다.
- Kubernetes 버전 차이 : 현재 Kubernetes 버전과 대상 버전 간의 차이와 애플리케이션 및 애드온의 호환성을 평가합니다.
- 리소스 제약 : 업그레이드 프로세스 중에 여러 클러스터를 유지하기 위한 사용 가능한 인프라 리소스와 예산을 고려하세요. 블루/그린과 유사한 카나리아 전략은 워크로드를 늘리는 동안 이전 클러스터를 확장하는 동안 새 클러스터를 확장하는 것을 제외하고는 이를 최소화합니다.
- 팀 전문성 : 여러 클러스터를 관리하고 트래픽 전환 전략을 구현하는 데 대한 팀의 전문성과 익숙함을 평가합니다.
의사결정 흐름 차트

▶ Kubernetes 버전 스큐를 사용한 증분형 인플레이스 업그레이드 전략
최신 Kubernetes 릴리스보다 여러 버전이 뒤떨어져 있고 인플레이스 업그레이드를 수행해야 하는 고객의 경우 Kubernetes의 버전 스큐 지원을 활용하는 것이 특히 유용할 수 있습니다. 이 전략을 사용하면 허용되는 최대 버전 스큐에 도달할 때까지 작업자 노드 업그레이드를 연기하면서 EKS 제어 평면을 점진적으로 업그레이드할 수 있습니다.
업그레이드 프로세스:
- EKS 제어 평면을 다음 마이너 버전으로 업그레이드합니다. Kubernetes는 제어 평면이 작업자 노드보다 최대 2개의 마이너 버전(또는 Kubernetes 1.28부터 3개의 마이너 버전) 앞설 수 있는 버전 왜곡을 지원합니다.
- 제어 평면이 최대 허용 스큐를 초과하는 버전으로 업그레이드될 때까지 기존 버전에서 작업자 노드를 유지합니다. 예를 들어, 제어 평면을 1.21에서 시작하고 작업자 노드를 1.21에서 시작하는 경우 작업자 노드를 업그레이드하지 않고도 제어 평면을 1.22, 1.23 및 1.24로 업그레이드할 수 있습니다.
- 제어 평면이 허용되는 최대 스큐를 초과하는 버전(예: 작업자가 여전히 1.21을 사용하고 있는 경우 1.24)에 도달하면 제어 평면을 추가로 업그레이드하기 전에 지원되는 스큐 범위 내의 버전(예: 1.22 또는 1.23)으로 작업자 노드를 업그레이드합니다.
- 제어 평면과 작업자 노드 모두에서 원하는 Kubernetes 버전에 도달할 때까지 1~3단계를 반복합니다.
이상적인 사용 사례:
- 최신 Kubernetes 릴리스보다 여러 버전 뒤쳐져 있으며 점진적으로 따라잡고 싶어합니다.
- 작업자 노드에는 광범위한 테스트가 필요하고 빈번한 업그레이드를 어렵게 만드는 복잡하고 상태 저장형 워크로드가 있습니다.
- 작업자 노드의 중단을 최소화하면서 새로운 기능과 버그 수정에 액세스하기 위해 정기적으로 제어 평면 업그레이드를 수행하려고 합니다.
고려 사항:
- 워커 노드가 호환 버전으로 업그레이드될 때까지 일부 새로운 Kubernetes 기능, 성능 개선 및 버그 수정을 완전히 사용할 수 없을 수 있습니다.
- 여러 버전을 건너뛴 후 워커 노드를 업그레이드하는 경우 호환성을 보장하고 문제를 식별하기 위해 철저한 테스트가 중요합니다.
- 이 전략은 유연성을 제공하지만, 비호환성 위험을 최소화하고 클러스터 전체에서 일관된 기능 세트를 보장하기 위해 제어 평면과 작업자 노드 버전을 최대한 가깝게 유지하는 것이 좋습니다.
Kubernetes의 버전 스큐 지원을 활용하면 이전 버전에서 시작하더라도 EKS 클러스터의 증분적 인플레이스 업그레이드를 수행할 수 있습니다. 이 접근 방식을 사용하면 워크로드 중단을 최소화하면서 Kubernetes 버전을 점진적으로 따라잡을 수 있습니다.
이러한 권장 사항은 일반적인 지침으로 사용되며, 선택하는 구체적인 접근 방식은 고유한 요구 사항, 제약 조건 및 위험 허용 범위에 따라 달라집니다. 업그레이드 전략을 결정할 때 클러스터의 특성, 작업 부하 요구 사항 및 조직의 우선순위를 신중하게 평가하는 것이 필수적입니다. 또한 선택한 업그레이드 접근 방식에 관계없이 잘 정의된 테스트 및 검증 계획을 수립하는 것이 중요합니다. 프로덕션 업그레이드를 진행하기 전에 비프로덕션 환경에서 애플리케이션, 애드온 및 통합을 철저히 테스트하여 잠재적인 문제를 식별하고 해결하세요.
마지막으로, 업그레이드 프로세스 중 및 이후에 발생할 수 있는 문제를 감지하고 문제를 해결하기 위한 포괄적인 모니터링 및 로깅 메커니즘이 있는지 확인하십시오. 습득한 교훈과 진화하는 모범 사례를 기반으로 업그레이드 전략을 정기적으로 검토하고 업데이트하여 EKS 클러스터 관리 관행을 지속적으로 개선하십시오.
▶ 결론
Amazon EKS 클러스터를 업그레이드하는 것은 최신 Kubernetes 기능, 보안 패치 및 성능 개선을 활용할 수 있도록 하는 중요한 프로세스입니다. 적절한 업그레이드 전략을 선택하는 것은 다운타임을 최소화하고, 위험을 줄이며, 새로운 Kubernetes 버전으로의 원활한 전환을 보장하는 데 필수적입니다.
이 모듈에서는 두 가지 주요 업그레이드 전략인 In-Place 업그레이드와 Blue-Green 업그레이드를 살펴보았습니다. 각 접근 방식의 장단점을 논의하고 다운타임 허용 범위, 업그레이드 복잡성, 리소스 제약, 규제 요구 사항 등 다양한 시나리오와 요인에 따라 권장 사항을 제공했습니다.
이 모듈의 주요 내용은 다음과 같습니다.
- 제자리 업그레이드는 다운타임 허용 범위가 낮은 부 버전 업그레이드에 적합한 반면, 블루-그린 업그레이드는 주요 버전 업그레이드나 상태 복잡도가 높은 애플리케이션에 권장됩니다.
- 성공적인 업그레이드를 위해서는 선택한 전략에 관계없이 신중한 계획, 테스트 및 검증이 필수적입니다.
- 업그레이드 프로세스 중에 문제를 신속하게 식별하고 해결하려면 모니터링, 로깅 및 명확하게 정의된 롤백 계획이 필수적입니다.
- 습득한 교훈과 진화하는 모범 사례를 기반으로 업그레이드 전략을 지속적으로 평가하고 최적화하는 것은 EKS 클러스터 관리 관행을 개선하는 데 중요합니다.
EKS 클러스터 업그레이드를 계획할 때 다음 모범 사례를 고려하세요.
- 클러스터의 특성, 작업 부하 요구 사항, 조직의 우선순위를 철저히 평가하여 가장 적합한 업그레이드 전략을 선택하세요.
- 호환성을 보장하고 문제 위험을 최소화하기 위해 포괄적인 테스트 및 검증 계획을 개발합니다.
- 애플리케이션 소유자, 규정 준수 관리자, 사용자 등 관련 이해 관계자와 협력하여 업그레이드 계획을 해당 요구 사항과 기대치에 맞게 조정합니다.
- 자동화 및 IaC(Infrastructure as Code) 도구를 활용하여 업그레이드 프로세스를 간소화하고 여러 환경 간의 일관성을 보장합니다.
- 이전 업그레이드에서 얻은 새로운 모범 사례와 교훈을 통합하여 업그레이드 전략을 정기적으로 검토하고 업데이트하세요.
이 모듈에서 제공하는 가이드라인과 권장 사항을 따르면 정보에 입각한 결정을 내리고 조직의 필요와 목표에 맞는 강력한 업그레이드 전략을 개발할 수 있습니다.
추가 자료
EKS 클러스터 업그레이드에 대한 최신 모범 사례와 도구에 대한 지식을 더욱 확장하고 최신 정보를 얻으려면 다음 리소스를 살펴보세요.
이러한 리소스를 활용하고 Kubernetes 및 AWS 커뮤니티에 적극적으로 참여하면 기술과 지식을 지속적으로 향상시켜 빠르게 변화하는 환경에서 EKS 클러스터를 효과적으로 관리하고 업그레이드할 수 있습니다.
4. 실습 - 시나리오
4-1. In-place Cluster Upgrade : 1.25 → 1.26
[ 들어가며 ]
1. 사전준비
- Kubernetes와 EKS의 릴리스 노트를 검토하세요.
- 추가 기능의 호환성을 검토하세요. Kubernetes 애드온과 사용자 정의 컨트롤러를 업그레이드하세요.
- 워크로드에서 더 이상 사용되지 않거나 삭제된 API 사용을 식별하고 수정합니다.
- 클러스터를 백업합니다(필요한 경우).
2. 업그레이드 단계
- 클러스터 제어 평면 업그레이드
- Kubernetes 애드온 및 사용자 정의 컨트롤러를 업데이트하세요.
- 클러스터의 노드를 업그레이드하세요
☞ 필요한 경우 사용되지 않는 API를 제거하고 Kubernetes 매니페스트를 업데이트하여 적절한 리소스를 수정한 후, 위의 순서대로 클러스터를 업그레이드할 수 있습니다. 이러한 단계는 테스트 환경에서 완료하는 것이 가장 좋으므로 프로덕션 클러스터에서 업그레이드 작업을 시작하기 전에 클러스터 구성과 애플리케이션 매니페스트의 문제를 발견할 수 있습니다.
Step1. Control-Plane Upgrade
☞ Amazon EKS에서 클러스터를 실행하는 가장 큰 이점 중 하나는 클러스터 제어부의 업그레이드가 단일 완전 자동화된 작업이라는 것입니다. 업그레이드하는 동안 현재 제어 평면 구성 요소는 파란색/녹색 방식으로 업그레이드됩니다. 문제가 발생하면 업그레이드가 롤백되고 애플리케이션은 계속 작동하고 사용 가능합니다.
One of the great benefits of running your clusters in Amazon EKS is that the upgrade of the cluster control plane is a single fully-automated operation. During Upgrade, the current control plane components are upgraded in blue/green fashion. If any issues arise, the upgrade is rolled back, and your applications remain up and available.
☞ 인플레이스 업그레이드는 다음으로 높은 Kubernetes 마이너 버전까지 점진적으로 진행되므로 현재 버전과 대상 버전 사이에 여러 릴리스가 있는 경우 순서대로 각 릴리스를 거쳐야 합니다. 다양한 요소를 고려하고 특정 요구 사항과 제약 조건에 가장 적합한 접근 방식을 평가하는 것이 중요합니다. 인플레이스 업그레이드 전략과 블루그린 업그레이드 전략 선택 참조
In-place upgrades are incremental to the next highest Kubernetes minor version, which means if you have several releases between your current and target versions, you’ll need to move through each one in sequence. It's essential to consider various factors and evaluate which approach best suits your specific requirements and constraints. Please refer Choosing between In-Place vs Blue-Green Upgrade Strategy before moving ahead with upgrades.
☞ 제어 평면을 업그레이드하기 전의 기본 Amazon EKS 요구 사항입니다.
- Amazon EKS는 클러스터를 업데이트하기 위해 클러스터를 생성할 때 지정한 서브넷에서 최대 5개의 사용 가능한 IP 주소가 필요합니다. IP를 사용할 수 없는 경우 버전 업데이트를 수행하기 전에 "UpdateClusterConfiguration" API를 사용하여 클러스터 구성을 업데이트하여 새 클러스터 서브넷을 포함하거나 기존 VPC CIDR 블록의 IP 주소가 부족하면 추가 CIDR 블록을 연결하는 것을 고려하세요.
- 제어 평면 IAM 역할은 필요한 권한이 있는 계정에 있어야 합니다.
- 클러스터에 비밀 암호화가 활성화된 경우 클러스터 IAM 역할에 AWS Key Management Service(AWS KMS) 키를 사용할 수 있는 권한이 있는지 확인해야 합니다.
☞ 업그레이드를 시작하면 AWS가 EKS 제어 평면을 업그레이드하는 단계에 대한 자세한 분석은 다음과 같습니다.
- 업그레이드 사전 검사:
- 업그레이드를 시작하기 전에 고객은 EKS 업그레이드 인사이트를 활용하여 업그레이드 사전 검사를 수행하고, EKS 클러스터를 최신 버전의 Kubernetes로 업그레이드하는 데 영향을 줄 수 있는 문제에 대한 결과를 수정하기 위한 권장 사항을 사용할 수 있습니다.
- 제어 평면 구성 요소 업그레이드:Upgrades for control plane components are handled in blue/green fashion. On completion of upgrade process, control plane API server endpoints are refreshed. Whole upgrade process is gracefully handled.
- 제어 평면 구성 요소에 대한 업그레이드는 블루/그린 방식으로 처리됩니다. 업그레이드 프로세스가 완료되면 제어 평면 API 서버 엔드포인트가 refreshed 됩니다. 전체 업그레이드 프로세스가 우아하게 처리됩니다.
- 이전 제어 평면 구성 요소 종료: 업그레이드가 완료되면 이전 제어 평면 구성 요소가 종료됩니다. The old control plane components are terminated once the upgrade is complete.
업그레이드는 블루/그린 방식으로 이루어지므로 EKS 업그레이드가 실패할 경우 중단을 최소화할 수 있습니다.
- 실패 감지: AWS는 업그레이드 프로세스를 지속적으로 모니터링하여 문제를 감지합니다. 제어 평면 업그레이드 중에 문제가 발생하면 프로세스가 즉시 중단됩니다.
- 새로운 제어 평면 구성 요소 종료: AWS는 업그레이드 중에 발생하는 새로운 제어 평면 구성 요소를 종료합니다.
- 롤백 후 평가: AWS는 업그레이드 실패의 이유를 평가하고 문제를 해결하는 방법에 대한 지침을 제공합니다. 고객은 업그레이드를 다시 시도하기 전에 문제를 해결하고 해결해야 합니다.
[ 업그레이드 방법 - 4가지 ]
방법1. eksctl 아래 실행하지 않음!
- 이 명령에서 대상 버전을 지정할 수 있지만 --version에 허용되는 값은 클러스터의 현재 버전 또는 한 버전 더 높은 버전입니다. 현재 두 개 이상의 Kubernetes 버전 업그레이드는 지원되지 않습니다.
eksctl upgrade cluster --name $EKS_CLUSTER_NAME --approve
방법2. AWS 관리 콘솔 : skip , 아래 실행하지 않음!

방법3. aws cli 아래 실행하지 않음!
- 클러스터에 관리되는 노드 그룹이 연결되어 있는 경우, 클러스터를 새로운 Kubernetes 버전으로 업데이트하려면 모든 노드 그룹의 Kubernetes 버전이 클러스터의 Kubernetes 버전과 일치해야 합니다.
aws eks update-cluster-version --region ${AWS_REGION} --name $EKS_CLUSTER_NAME --kubernetes-version 1.26
{
"update": {
"id": "b5f0ba18-9a87-4450-b5a0-825e6e84496f",
"status": "InProgress",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "PlatformVersion",
"value": "eks.1"
}
],
[...]
"errors": []
}
}
# 다음 명령으로 클러스터 업데이트 상태를 모니터링할 수 있습니다. 이전 명령에서 반환한 클러스터 이름과 업데이트 ID를 사용합니다.
# Successful 상태가 표시되면 업데이트가 완료된 것입니다.
aws eks describe-update --region ${AWS_REGION} --name $EKS_CLUSTER_NAME --update-id b5f0ba18-9a87-4450-b5a0-825e6e84496f
방법4. 테라폼으로 업그레이드 - 본 실습에서는 해당 방법으로 업그레이드 수행한다!!
#
cd ~/environment/terraform
terraform state list
Step1. 진행 상태 모니터링
# 현재 버전 확인 : 파일로 저장해두기
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.25.txt
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon-k8s-cni:v1.19.3-eksbuild.1
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon/aws-network-policy-agent:v1.2.0-eksbuild.1
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/aws-ebs-csi-driver:v1.41.0
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/coredns:v1.8.7-eksbuild.10
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-attacher:v4.8.1-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-node-driver-registrar:v2.13.0-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-provisioner:v5.2.0-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-resizer:v1.13.2-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-snapshotter:v8.2.1-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.25.16-minimal-eksbuild.8
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/livenessprobe:v2.14.0-eks-1-32-7
8 amazon/aws-efs-csi-driver:v1.7.6
1 amazon/dynamodb-local:1.13.1
1 ghcr.io/dexidp/dex:v2.38.0
1 hjacobs/kube-ops-view:20.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-assets:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-cart:0.7.0
1 public.ecr.aws/aws-containers/retail-store-sample-catalog:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-checkout:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-orders:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-ui:0.4.0
1 public.ecr.aws/bitnami/rabbitmq:3.11.1-debian-11-r0
2 public.ecr.aws/docker/library/mysql:8.0
1 public.ecr.aws/docker/library/redis:6.0-alpine
1 public.ecr.aws/docker/library/redis:7.0.15-alpine
2 public.ecr.aws/eks-distro/kubernetes-csi/external-provisioner:v3.6.3-eks-1-29-2
8 public.ecr.aws/eks-distro/kubernetes-csi/livenessprobe:v2.11.0-eks-1-29-2
6 public.ecr.aws/eks-distro/kubernetes-csi/node-driver-registrar:v2.9.3-eks-1-29-2
2 public.ecr.aws/eks/aws-load-balancer-controller:v2.7.1
2 public.ecr.aws/karpenter/controller:0.37.0@sha256:157f478f5db1fe999f5e2d27badcc742bf51cc470508b3cebe78224d0947674f
5 quay.io/argoproj/argocd:v2.10.0
1 registry.k8s.io/metrics-server/metrics-server:v0.7.0
# IDE-Server 혹은 자신의 PC에서 반복 접속 해두자!
export UI_WEB=$(kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}'/actuator/health/liveness)
curl -s $UI_WEB ; echo
{"status":"UP"}
# 반복 접속 1
UI_WEB=k8s-ui-uinlb-d75345d621-e2b7d1ff5cf09378.elb.us-west-2.amazonaws.com/actuator/health/liveness
while true; do curl -s $UI_WEB ; date; sleep 1; echo; done
# 반복 접속 2 : aws cli 자격증명 설정 필요
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
"version": "1.25",
"endpoint": "https://A77BDC5EEBAE5EC887F1747B6AE965B3.gr7.us-west-2.eks.amazonaws.com",
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/A77BDC5EEBAE5EC887F1747B6AE965B3"
"platformVersion": "eks.44",
# 반복 접속 2
while true; do curl -s $UI_WEB; date; aws eks describe-cluster --name eksworkshop-eksctl | egrep 'version|endpoint"|issuer|platformVersion'; echo ; sleep 2; echo; done
Step2. variable.tf의 cluster_version 변수를 1.25 -> 1.26 으로 수정
☞ eks 모듈에서 eks 클러스터 구성을 볼 수 있습니다 base.tf. cluster_version의 값은 variable.tf의 변수 cluster_version에 정의되어 있습니다. 현재는 1.25 으로 설정 되어 있습니다.
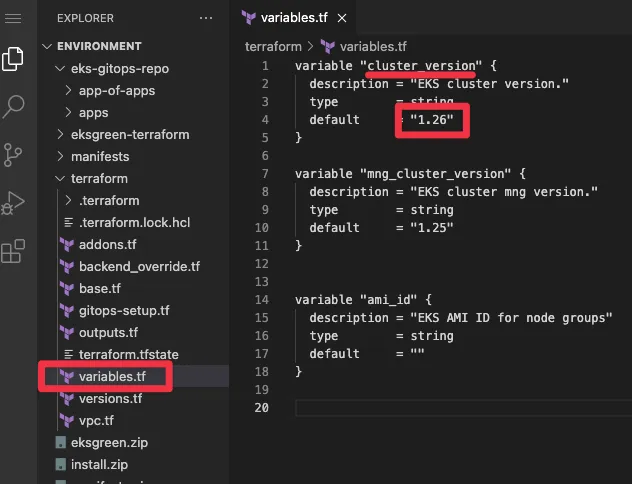

# 기본 정보
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# Plan을 적용하면 Terraform이 어떤 변경을 하는지 볼 수 있습니다.
terraform plan
terraform plan -no-color > plan-output.txt # IDE에서 열어볼것
...
<= data "tls_certificate" "this" {
+ certificates = (known after apply)
+ id = (known after apply)
+ url = "https://oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059"
}
# module.eks.aws_iam_openid_connect_provider.oidc_provider[0] will be updated in-place
~ resource "aws_iam_openid_connect_provider" "oidc_provider" {
id = "arn:aws:iam::271345173787:oidc-provider/oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
"Name" = "eksworkshop-eksctl-eks-irsa"
"karpenter.sh/discovery" = "eksworkshop-eksctl"
}
~ thumbprint_list = [
- "9e99a48a9960b14926bb7f3b02e22da2b0ab7280",
] -> (known after apply)
# (4 unchanged attributes hidden)
}
# module.eks_blueprints_addons.data.aws_eks_addon_version.this["aws-ebs-csi-driver"] will be read during apply
# (depends on a resource or a module with changes pending)
<= data "aws_eks_addon_version" "this" {
+ addon_name = "aws-ebs-csi-driver"
+ id = (known after apply)
+ kubernetes_version = "1.26"
+ most_recent = true
+ version = (known after apply)
}
# module.eks_blueprints_addons.aws_eks_addon.this["vpc-cni"] will be updated in-place
~ resource "aws_eks_addon" "this" {
~ addon_version = "v1.19.3-eksbuild.1" -> (known after apply)
id = "eksworkshop-eksctl:vpc-cni"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
# (11 unchanged attributes hidden)
# (1 unchanged block hidden)
}
# module.eks_blueprints_addons.aws_iam_role_policy_attachment.karpenter["AmazonEC2ContainerRegistryReadOnly"] must be replaced
-/+ resource "aws_iam_role_policy_attachment" "karpenter" {
~ id = "karpenter-eksworkshop-eksctl-20250325094537762400000002" -> (known after apply)
~ policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly" -> (known after apply) # forces replacement
# (1 unchanged attribute hidden)
}
# module.eks_blueprints_addons.module.aws_efs_csi_driver.data.aws_iam_policy_document.assume[0] will be read during apply
# (depends on a resource or a module with changes pending)
<= data "aws_iam_policy_document" "assume" {
+ id = (known after apply)
+ json = (known after apply)
+ minified_json = (known after apply)
+ statement {
+ actions = [
+ "sts:AssumeRoleWithWebIdentity",
]
+ effect = "Allow"
+ condition {
+ test = "StringEquals"
+ values = [
+ "sts.amazonaws.com",
]
+ variable = "oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059:aud"
}
+ condition {
+ test = "StringEquals"
+ values = [
+ "system:serviceaccount:kube-system:efs-csi-controller-sa",
]
+ variable = "oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059:sub"
}
+ principals {
+ identifiers = [
+ "arn:aws:iam::271345173787:oidc-provider/oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059",
]
+ type = "Federated"
}
}
+ statement {
+ actions = [
+ "sts:AssumeRoleWithWebIdentity",
]
+ effect = "Allow"
+ condition {
+ test = "StringEquals"
+ values = [
+ "sts.amazonaws.com",
]
+ variable = "oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059:aud"
}
+ condition {
+ test = "StringEquals"
+ values = [
+ "system:serviceaccount:kube-system:efs-csi-node-sa",
]
+ variable = "oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059:sub"
}
+ principals {
+ identifiers = [
+ "arn:aws:iam::271345173787:oidc-provider/oidc.eks.us-west-2.amazonaws.com/id/B852364D70EA6D62672481D278A15059",
]
+ type = "Federated"
}
}
}
# 기본 정보
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# 클러스터 버전을 변경하면 테라폼 계획에 표시된 것처럼, 관리 노드 그룹에 대한 특정 버전이나 AMI가 테라폼 파일에 정의되지 않은 경우,
# eks 클러스터 제어 평면과 관리 노드 그룹 및 애드온과 같은 관련 리소스를 업데이트하게 됩니다.
# 이 계획을 적용하여 제어 평면 버전을 업데이트해 보겠습니다.
terraform apply -auto-approve # 10분 소요
# eks control plane 1.26 업글 확인
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq
...
"version": "1.26",
# endpoint, issuer, platformVersion 동일 => IRSA 를 사용하는 4개의 App 동작에 문제 없음!
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# 파드 컨테이너 이미지 버전 모두 동일
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.26.txt
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
diff 1.26.txt 1.25.txt # 동일함
# 파드 AGE 정보 확인 : 재생성된 파드 없음!
kubectl get pod -A
...
☞ AWS console에서 업그레이드 결과 확인 !!
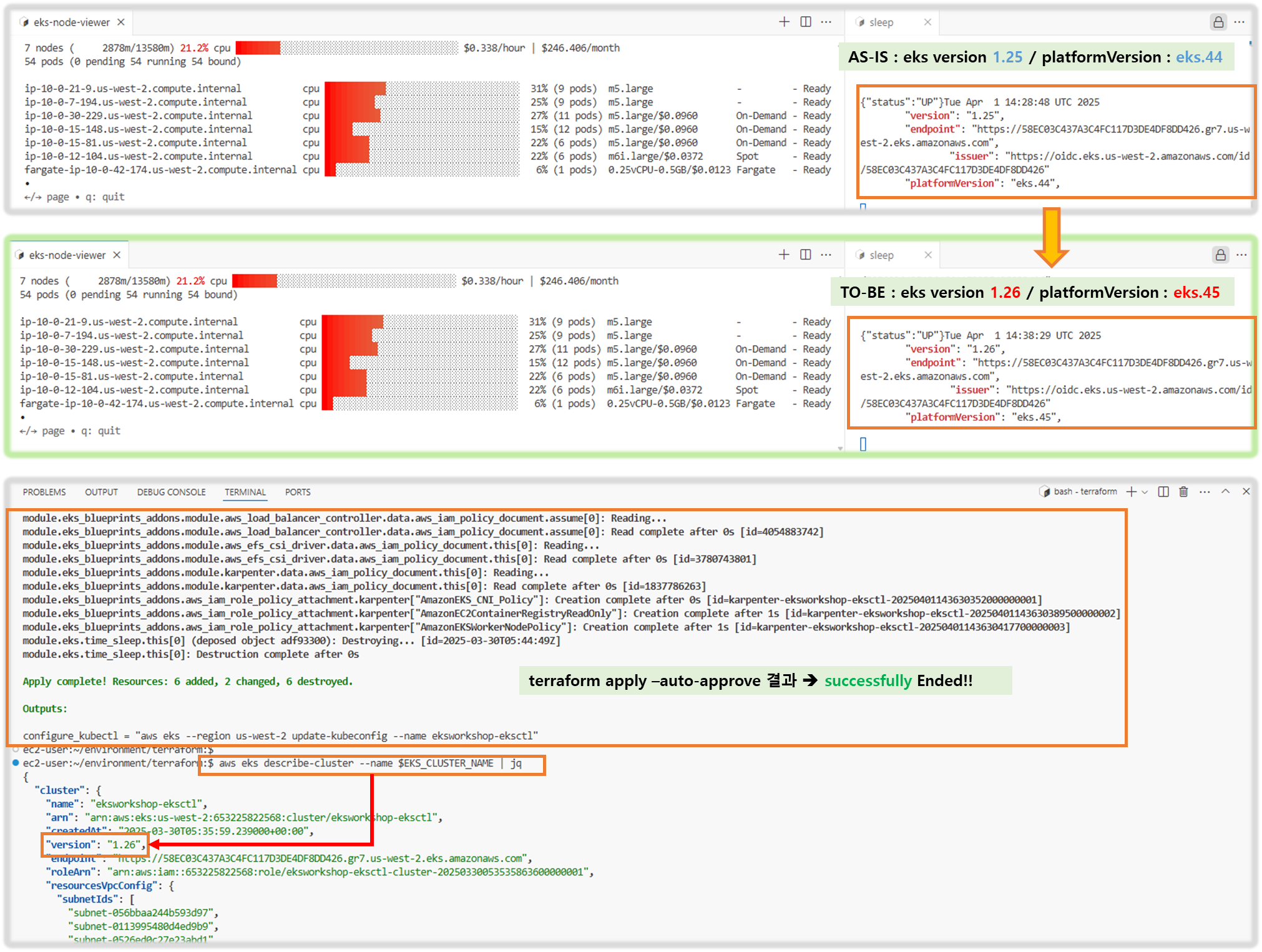
Step3. Control Plane Upgrade 후 상태 확인 - HPA 문제해결
☞ Cluster Insight

☞ Insight: EKS add-on version compatibility

☞ Insight: Kubelet version skew

☞ Insight: kube-proxy version skew
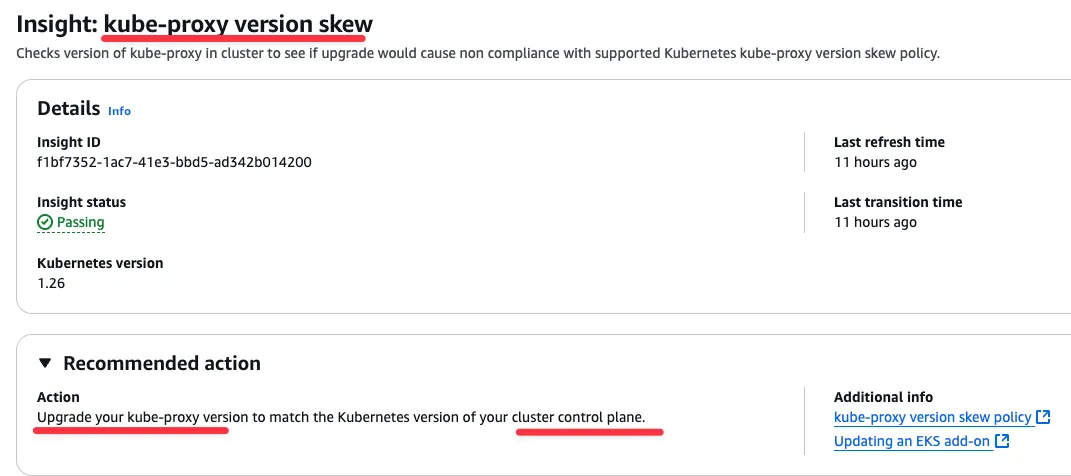
☞ Insight: Deprecated APIs removed in Kubernetes v1.26

☞ Argo CD 에 ui app(HPA 리소스) 상태 확인
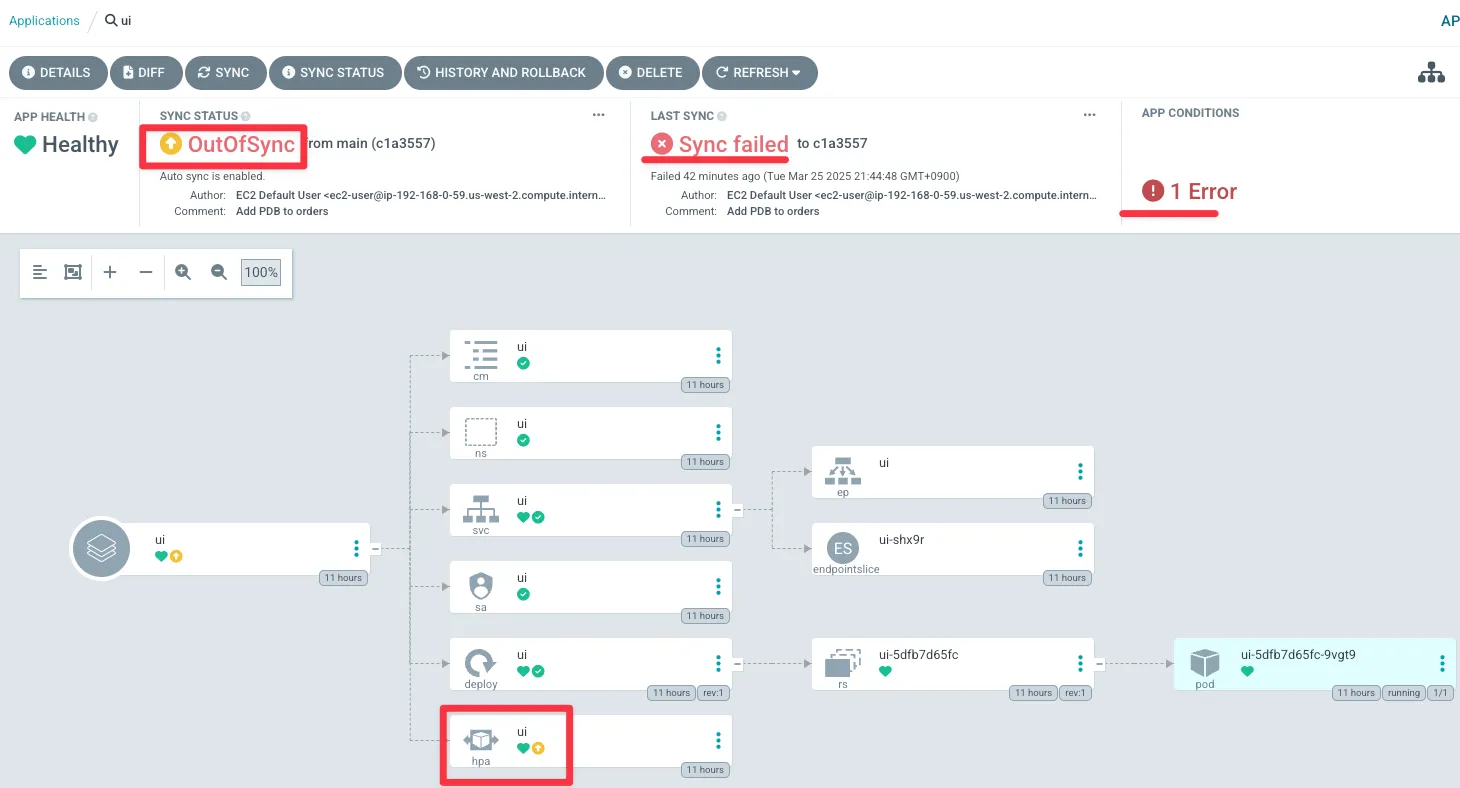

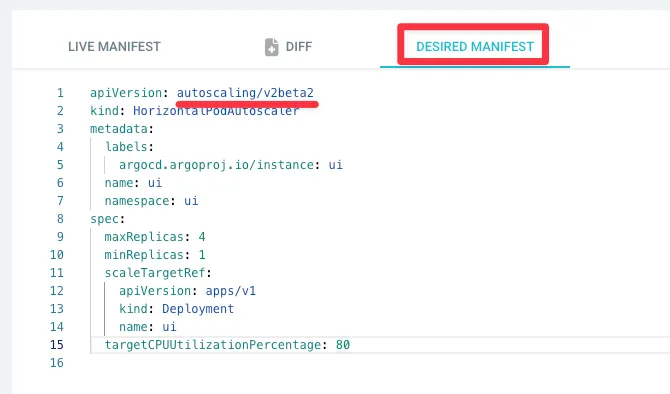
#
kubectl get hpa -n ui ui -o yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"autoscaling/v2beta2","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"labels":{"argocd.argoproj.io/instance":"ui"},"name":"ui","namespace":"ui"},"spec":{"maxReplicas":4,"minReplicas":1,"scaleTargetRef":{"apiVersion":"apps/v1","kind":"Deployment","name":"ui"},"targetCPUUtilizationPercentage":80}}
creationTimestamp: "2025-03-25T02:40:17Z"
labels:
argocd.argoproj.io/instance: ui
...
kubectl get hpa -n ui ui -o json | jq -r '.metadata.annotations."kubectl.kubernetes.io/last-applied-configuration"' | jq
{
"apiVersion": "autoscaling/v2beta2",
"kind": "HorizontalPodAutoscaler",
"metadata": {
"annotations": {},
"labels": {
"argocd.argoproj.io/instance": "ui"
},
"name": "ui",
"namespace": "ui"
},
"spec": {
"maxReplicas": 4,
"minReplicas": 1,
"scaleTargetRef": {
"apiVersion": "apps/v1",
"kind": "Deployment",
"name": "ui"
},
"targetCPUUtilizationPercentage": 80
}
}
#
kubectl get hpa -n ui ui -o yaml | kubectl neat > hpa-ui.yaml
kubectl convert -f hpa-ui.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: null
labels:
argocd.argoproj.io/instance: ui
name: ui
namespace: ui
spec:
maxReplicas: 4
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ui
status:
currentMetrics: null
desiredReplicas: 0
☞ UI HPA API 문제 해결 ⇒ 아직은 해결하지 말고 두자. 뒤에 시나리오에서 문제 확인 및 조치되는 걸로 알고 있음!
#
cat ~/environment/eks-gitops-repo/apps/ui/hpa.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: ui
namespace: ui
spec:
minReplicas: 1
maxReplicas: 4
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ui
# HIGHLIGHT
targetCPUUtilizationPercentage: 80
#
cat << EOF > ~/environment/eks-gitops-repo/apps/ui/hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ui
namespace: ui
spec:
minReplicas: 1
maxReplicas: 4
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ui
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
EOF
cat ~/environment/eks-gitops-repo/apps/ui/hpa.yaml
#
cd ~/environment/eks-gitops-repo/
git add apps/ui/hpa.yaml
git commit -m "Modify to ui hpa"
git push
argocd app sync ui
...
Operation: Sync
Sync Revision: faa1fcf08e679be8e6dff57ddd081e8562270edf
Phase: Succeeded
Start: 2025-03-25 13:49:32 +0000 UTC
Finished: 2025-03-25 13:49:33 +0000 UTC
Duration: 1s
Message: successfully synced (all tasks run)
Step2. Addons Upgrade
EKS 업그레이드의 일부로 클러스터에 설치된 애드온을 업그레이드해야 합니다. 애드온은 K8s 애플리케이션에 지원 운영 기능을 제공하는 소프트웨어로, 네트워킹, 컴퓨팅 및 스토리지를 위해 클러스터가 기본 AWS 리소스와 상호 작용할 수 있도록 하는 관찰 에이전트 또는 Kubernetes 드라이버와 같은 소프트웨어가 포함됩니다. 애드온 소프트웨어는 일반적으로 Kubernetes 커뮤니티, AWS와 같은 클라우드 공급자 또는 타사 공급업체에서 빌드하고 유지 관리합니다.
Amazon EKS 애드온을 사용하면 Amazon EKS 클러스터가 안전하고 안정적임을 지속적으로 보장하고 애드온을 설치, 구성 및 업데이트하는 데 필요한 작업량을 줄일 수 있습니다. Amazon EKS의 Amazon EKS 애드온 목록
대상1. CoreDNS (여기서 호환성을 확인할 수 있습니다)
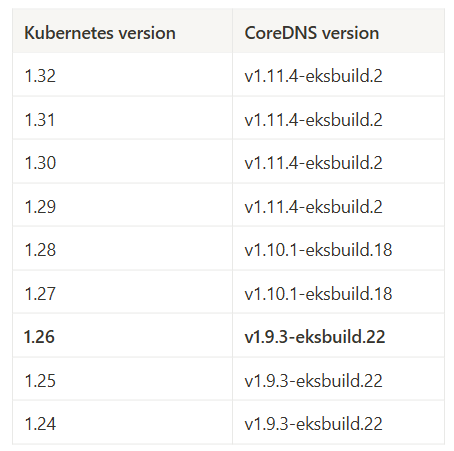
대상2. kube-proxy (여기서 호환성을 확인할 수 있습니다)

대상3. VPC CNI (여기서 호환성을 확인할 수 있습니다)

☞ eksctl을 사용하여 EKS 1.25의 기존 애드온을 보려면 : 가능한 업그레이드 버전 정보 확인!
# 가능한 업그레이드 버전 정보 확인
eksctl get addon --cluster $CLUSTER_NAME
NAME VERSION STATUS ISSUES IAMROLE UPDATE AVAILABLE CONFIGURATION VALUES
aws-ebs-csi-driver v1.41.0-eksbuild.1 ACTIVE 0 arn:aws:iam::271345173787:role/eksworkshop-eksctl-ebs-csi-driver-2025032502294618580000001d
coredns v1.8.7-eksbuild.10 ACTIVE 0 v1.9.3-eksbuild.22,v1.9.3-eksbuild.21,v1.9.3-eksbuild.19,v1.9.3-eksbuild.17,v1.9.3-eksbuild.15,v1.9.3-eksbuild.11,v1.9.3-eksbuild.10,v1.9.3-eksbuild.9,v1.9.3-eksbuild.7,v1.9.3-eksbuild.6,v1.9.3-eksbuild.5,v1.9.3-eksbuild.3,v1.9.3-eksbuild.2
kube-proxy v1.25.16-eksbuild.8 ACTIVE 0 v1.26.15-eksbuild.24,v1.26.15-eksbuild.19,v1.26.15-eksbuild.18,v1.26.15-eksbuild.14,v1.26.15-eksbuild.10,v1.26.15-eksbuild.5,v1.26.15-eksbuild.2,v1.26.13-eksbuild.2,v1.26.11-eksbuild.4,v1.26.11-eksbuild.1,v1.26.9-eksbuild.2,v1.26.7-eksbuild.2,v1.26.6-eksbuild.2,v1.26.6-eksbuild.1,v1.26.4-eksbuild.1,v1.26.2-eksbuild.1
vpc-cni v1.19.3-eksbuild.1 ACTIVE 0
☞ terraform을 사용하여 CoreDNS , kube-proxy 및 VPC CNI 의 업그레이드를 살펴보겠습니다. 이를 위해 파일에서 CoreDNS, kube-proxy 및 VPC CNI의 버전을 업데이트하기만 하면 됩니다 /home/ec2-user/environment/terraform/addons.tf.
eks_addons = {
coredns = {
addon_version = "v1.8.7-eksbuild.10"
}
kube-proxy = {
addon_version = "v1.25.16-eksbuild.8"
}
vpc-cni = {
most_recent = true
}
aws-ebs-csi-driver = {
service_account_role_arn = module.ebs_csi_driver_irsa.iam_role_arn
}
}
☞ Amazon EKS는 AWS Managed Addons에 대한 주어진 K8s 버전에 대한 호환되는 애드온 버전을 나열하는 API를 제공합니다. 다음 명령을 사용하여 1.26 호환되는 coredns애드온 버전을 찾을 수 있습니다.
#
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon-k8s-cni:v1.19.3-eksbuild.1
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/aws-ebs-csi-driver:v1.41.0
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/coredns:v1.8.7-eksbuild.10
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-provisioner:v5.2.0-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.25.16-minimal-eksbuild.8
8 amazon/aws-efs-csi-driver:v1.7.6
2 public.ecr.aws/eks/aws-load-balancer-controller:v2.7.1
#
aws eks describe-addon-versions --addon-name coredns --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
------------------------------------------
| DescribeAddonVersions |
+-----------------+----------------------+
| DefaultVersion | Version |
+-----------------+----------------------+
| False | v1.9.3-eksbuild.22 |
| False | v1.9.3-eksbuild.21 |
| False | v1.9.3-eksbuild.19 |
| False | v1.9.3-eksbuild.17 |
| False | v1.9.3-eksbuild.15 |
| False | v1.9.3-eksbuild.11 |
| False | v1.9.3-eksbuild.10 |
| False | v1.9.3-eksbuild.9 |
| True | v1.9.3-eksbuild.7 |
| False | v1.9.3-eksbuild.6 |
+-----------------+----------------------+
#
aws eks describe-addon-versions --addon-name kube-proxy --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
--------------------------------------------
| DescribeAddonVersions |
+-----------------+------------------------+
| DefaultVersion | Version |
+-----------------+------------------------+
| False | v1.26.15-eksbuild.24 |
| False | v1.26.15-eksbuild.19 |
| False | v1.26.15-eksbuild.18 |
| False | v1.26.15-eksbuild.14 |
| False | v1.26.15-eksbuild.10 |
| False | v1.26.15-eksbuild.5 |
| False | v1.26.15-eksbuild.2 |
| False | v1.26.13-eksbuild.2 |
| False | v1.26.11-eksbuild.4 |
| False | v1.26.11-eksbuild.1 |
+-----------------+------------------------+- 참고로 나머지 Addon 인 VPC CNI, EBS CSI Driver 는 현재 최신 버전 사용 중임 - 콘솔에서 addon 에서 Edit 로 버전 정보 확인
Step1. 위의 출력에서 최신 버전을 선택하여 addons.tf 아래에 표시된 대로 파일에 업데이트
대상 : /home/ec2-user/environment/terraform/addons.tf
eks_addons = {
coredns = {
version = "v1.9.3-eksbuild.22" # Recommended version for EKS 1.26
}
kube_proxy = {
version = "v1.26.15-eksbuild.24" # Recommended version for EKS 1.26
}
vpc-cni = {
most_recent = true
}
aws-ebs-csi-driver = {
service_account_role_arn = module.ebs_csi_driver_irsa.iam_role_arn
}
}
Step2. 적용 및 확인
# 반복 접속 : 아래 coredns, kube-proxy addon 업그레이드 시 ui 무중단 통신 확인!
aws eks update-kubeconfig --name eksworkshop-eksctl # 자신의 집 PC일 경우
kubectl get pod -n kube-system -l k8s-app=kube-dns
kubectl get pod -n kube-system -l k8s-app=kube-proxy
kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'
while true; do curl -s $UI_WEB ; date; kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'; echo ; sleep 2; done
#
cd ~/environment/terraform/
terraform plan -no-color | tee addon.txt
...
# module.eks_blueprints_addons.aws_eks_addon.this["coredns"] will be updated in-place
~ resource "aws_eks_addon" "this" {
~ addon_version = "v1.8.7-eksbuild.10" -> "v1.9.3-eksbuild.22"
id = "eksworkshop-eksctl:coredns"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
# (11 unchanged attributes hidden)
# (1 unchanged block hidden)
}
# module.eks_blueprints_addons.aws_eks_addon.this["kube-proxy"] will be updated in-place
~ resource "aws_eks_addon" "this" {
~ addon_version = "v1.25.16-eksbuild.8" -> "v1.26.15-eksbuild.24"
id = "eksworkshop-eksctl:kube-proxy"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
...
# 1분 정도 이내로 롤링 업데이트 완료!
terraform apply -auto-approve
#
kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'
NAME READY STATUS RESTARTS AGE
coredns-58cc4d964b-7867s 1/1 Running 0 71s
coredns-58cc4d964b-qb8zc 1/1 Running 0 71s
kube-proxy-2f6nv 1/1 Running 0 61s
kube-proxy-7n8xj 1/1 Running 0 67s
kube-proxy-7p4p2 1/1 Running 0 70s
kube-proxy-g2vvp 1/1 Running 0 54s
kube-proxy-ks4xp 1/1 Running 0 64s
kube-proxy-kxvh5 1/1 Running 0 57s
#
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/coredns:v1.9.3-eksbuild.22
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.26.15-minimal-eksbuild.24
...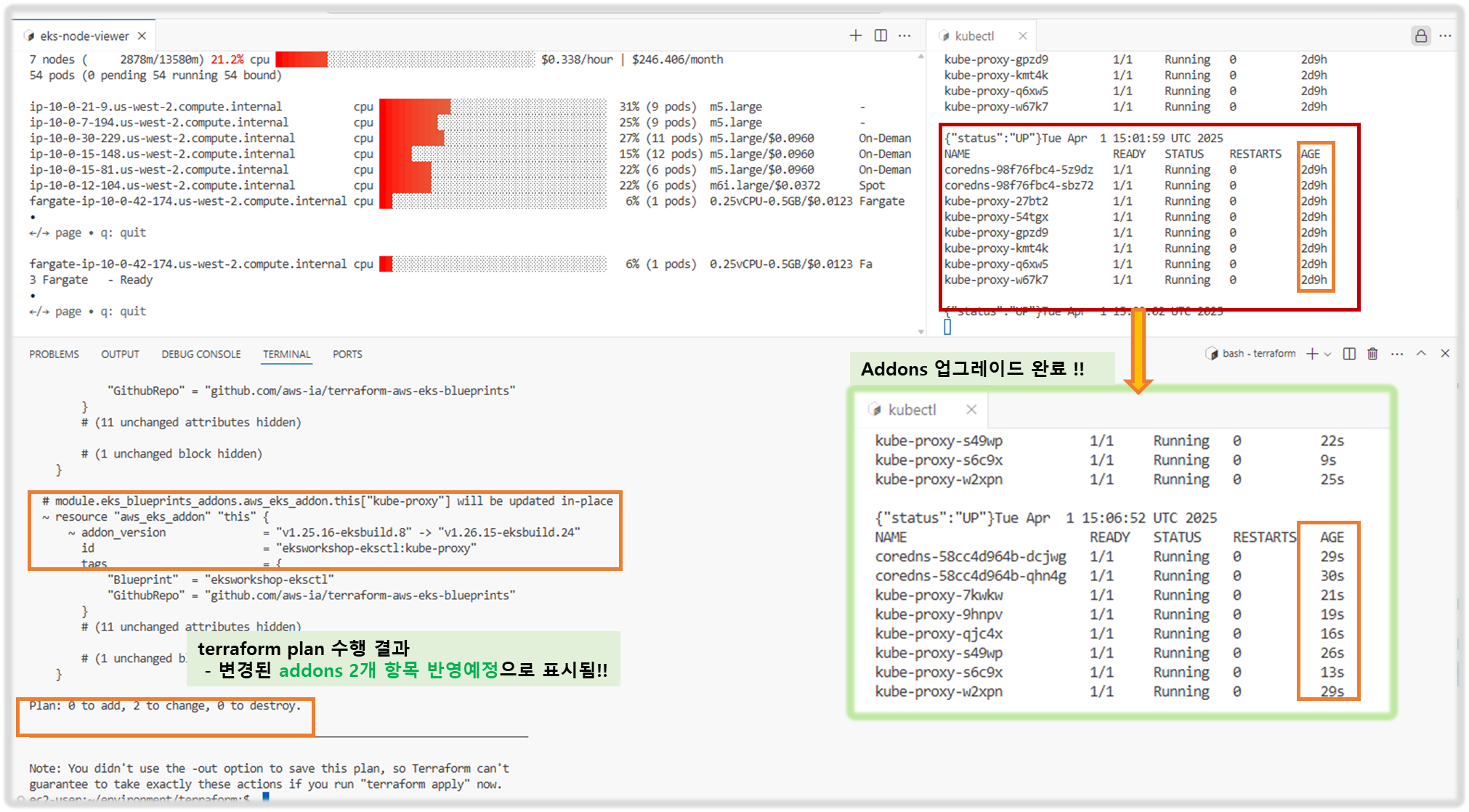
Step3-1. Data-Plane Upgrade [ Managed Node-group ]
☞ 업그레이드 전략 : 기존 EKS 관리 노드 그룹 업데이드(인플레이스) vs 새로운 EKS 관리 노드 그룹으로 마이그레이션(블루-그린)
- Amazon EKS 관리형 노드 그룹은 Amazon EKS 클러스터의 노드(Amazon EC2 인스턴스) 프로비저닝 및 수명 주기 관리를 자동화합니다.
- Amazon EKS 관리형 노드 그룹을 사용하면 Kubernetes 애플리케이션을 실행하기 위한 컴퓨팅 용량을 제공하는 Amazon EC2 인스턴스를 별도로 프로비저닝하거나 등록할 필요가 없습니다. 단일 작업으로 클러스터에 대한 노드를 생성, 자동 업데이트 또는 종료할 수 있습니다. 노드 업데이트 및 종료는 노드를 자동으로 비워 애플리케이션이 계속 사용 가능한 상태를 유지하도록 합니다.
- 모든 관리 노드는 Amazon EKS에서 관리하는 Amazon EC2 Auto Scaling 그룹의 일부로 프로비저닝됩니다. 인스턴스와 Auto Scaling 그룹을 포함한 모든 리소스는 AWS 계정 내에서 실행됩니다. 각 노드 그룹은 사용자가 정의한 여러 가용성 영역에서 실행됩니다.
Step1. In-Place Managed Node group Upgrade* 20분 소요 실습 포함
관리 노드 그룹 업그레이드도 완전히 자동화되어 점진적인 롤링 업데이트로 구현됩니다.
새 노드는 EC2 자동 스케일링 그룹에 프로비저닝되고 클러스터에 합류하며, as old nodes는 cordoned, drained, and removed
기본적으로 새 노드는 최신 EKS 최적화 AMI(Amazon Machine Image) 또는 선택적으로 사용자 지정 AMI를 사용합니다.
참고로, 사용자 지정 AMI를 사용할 때는 업데이트된 이미지를 직접 만들어야 하므로 노드 그룹 업그레이드의 일환으로 업데이트된 Launch Template 버전이 필요합니다.
☞ 관리형 노드 그룹 업데이트를 시작하면 Amazon EKS가 자동으로 노드를 업데이트하여 아래 설명된 대로 4가지 단계를 완료
- 설정 단계:
- 노드 그룹과 연결된 자동 스케일링 그룹에 대한 새로운 Amazon EC2 launch template version을 생성합니다.
- The new launch template version은 업데이트에 target AMI 또는 custom launch template version for the update 를 사용합니다.
- Auto Scaling group을 최신 실행 템플릿 버전latest launch template version을 사용하도록 업데이트합니다.
- 노드 그룹에 대한 updateConfig 속성을 사용하여 병렬로 업그레이드할 최대 노드 수를 결정합니다.
- The maximum unavailable has a quota of 100 nodes. 기본값은 1개 노드입니다.
- 확장 단계: 확장 단계에는 다음 단계가 있습니다.
- 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 더 큰 크기로 증가시킵니다. It increments the Auto Scaling Group's maximum size and desired size by the larger of either
- 자동 확장 그룹이 배포된 가용성 영역 수의 최대 2배. Up to twice the number of Availability Zones that the Auto Scaling group is deployed in.
- 업그레이드가 불가능 한 최대 한도입니다. The maximum unavailable of upgrade.
- 자동 확장 그룹을 확장한 후 최신 구성을 사용하는 노드가 노드 그룹에 있고 준비되었는지 확인합니다.
- 그런 다음 노드를 예약 불가능으로 표시하여 새 Pod를 예약하지 않도록 합니다. It then marks nodes as un-schedulable to avoid scheduling new Pods.
- 또한 노드를 node.kubernetes.io/exclude-from-external-load-balancers=true 로 레이블하여 노드를 종료하기 전에 로드 밸런서에서 노드를 제거합니다. It also labels nodes with node.kubernetes.io/exclude-from-external-load-balancers=true to remove the nodes from load balancers before terminating the nodes.
- 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 더 큰 크기로 증가시킵니다. It increments the Auto Scaling Group's maximum size and desired size by the larger of either
- 업그레이드 단계:* 업그레이드 단계는 다음과 같은 단계로 구성됩니다.
- 노드 그룹에 대해 구성된 최대 사용 불가능 개수까지 업그레이드가 필요한 노드를 무작위로 선택합니다.
- It randomly selects a node that needs to be upgraded, up to the maximum unavailable configured for the node group.
- 노드에서 Pod를 비웁니다. Pod가 15분 이내에 노드를 떠나지 않고 강제 플래그가 없으면 업그레이드 단계는 PodEvictionFailure 오류
- It drains the Pods from the node. If the Pods don't leave the node within 15 minutes and there's no force flag, the upgrade phase fails with a PodEvictionFailure error. For this scenario, you can apply the force flag with the update-nodegroup-version request to delete the Pods.
- 로 실패합니다 . 이 시나리오에서는 update-nodegroup-version 요청과 함께 강제 플래그를 적용하여 Pod를 삭제할 수 있습니다.
- 모든 Pod가 퇴거된 후 노드를 봉쇄하고 60초 동안 기다립니다. 이는 서비스 컨트롤러가 이 노드에 새로운 요청을 보내지 않고 이 노드를 활성 노드 목록에서 제거하기 위해 수행됩니다.
- It cordons the node after every Pod is evicted and waits for 60 seconds. This is done so that the service controller doesn't send any new requests to this node and removes this node from its list of active nodes.
- cordoned 노드에 대한 자동 확장 그룹에 종료 요청을 보냅니다.
- It sends a termination request to the Auto Scaling Group for the cordoned node.
- 이전 버전의 실행 템플릿을 사용하여 배포된 노드 그룹에 노드가 없을 때까지 이전 업그레이드 단계를 반복합니다.
- It repeats the previous upgrade steps until there are no nodes in the node group that are deployed with the earlier version of the launch template.
- 노드 그룹에 대해 구성된 최대 사용 불가능 개수까지 업그레이드가 필요한 노드를 무작위로 선택합니다.
- 축소 단계: 축소 단계에서는 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 하나씩 감소시켜 업데이트가 시작되기 전 값으로 돌아갑니다.
- 축소 단계는 자동 스케일링 그룹의 최대 크기와 원하는 크기를 하나씩 줄여 업데이트가 시작되기 전의 값으로 돌아갑니다.
방법 1 : eksctl, 아래 실행하지 않음!
# 우리는 사용 중인 AMI 유형의 Kubernetes 버전에 대한 최신 AMI 릴리스 버전으로 노드 그룹을 업데이트할 수 있습니다.
eksctl upgrade nodegroup --name=managed-ng-1 --cluster=$EKS_CLUSTER_NAME
# 노드 그룹이 클러스터의 Kubernetes 버전에서 이전 Kubernetes 버전인 경우, 다음을 통해 노드 그룹을 클러스터의 Kubernetes 버전과 일치하는 최신 AMI 릴리스 버전으로 업데이트할 수 있습니다.
eksctl upgrade nodegroup --name=managed-ng-1 --cluster=$EKS_CLUSTER_NAME --kubernetes-version=<control plane version>
# 최신 버전 대신 특정 AMI 릴리스 버전으로 업그레이드하려면 다음을 사용합니다.
eksctl upgrade nodegroup --name=managed-ng-1 --cluster=$EKS_CLUSTER_NAME --release-version=<specific AMI Release version>
방법 2 : AWS 관리 콘솔, 아래 실행하지 않음!

- 업데이트할 노드 그룹이 포함된 클러스터를 선택하세요.
- 하나 이상의 노드 그룹에 사용 가능한 업데이트가 있는 경우 페이지 상단에 사용 가능한 업데이트를 알려주는 상자가 나타납니다. Compute 탭을 선택하면 사용 가능한 업데이트가 있는 노드 그룹의 Node groups 표에서 AMI 릴리스 버전 열에 Update now가 표시됩니다. 노드 그룹을 업데이트하려면 Update now를 선택합니다 .
- 노드 그룹 버전 업데이트 대화 상자에서 다음 옵션을 활성화하거나 비활성화합니다.
- 노드 그룹 버전 업데이트 – 사용자 지정 AMI를 배포했거나 Amazon EKS 최적화 AMI가 현재 클러스터의 최신 버전인 경우 이 옵션을 사용할 수 없습니다.
- 출시 템플릿 버전 변경: 노드 그룹이 사용자 지정 출시 템플릿 없이 배포된 경우 이 옵션을 사용할 수 없습니다.
- 업데이트 전략의 경우 다음 옵션 중 하나를 선택하세요.
- 롤링 업데이트 - 이 옵션은 클러스터의 Pod 중단 예산을 존중합니다. Amazon EKS가 이 노드 그룹에서 실행 중인 Pod를 우아하게 비울 수 없게 하는 Pod 중단 예산 문제가 있는 경우 업데이트가 실패합니다.
- 강제 업데이트 - 이 옵션은 Pod 중단 예산을 존중하지 않습니다. Pod 중단 예산 문제와 관계없이 노드 재시작을 강제로 발생시켜 업데이트가 발생합니다.
- 업데이트를 선택하세요.
방법 3. Terraform , 해당 방법으로 실제 업그레이드 실행! 20분 소요 실습 포함
☞ Control Plane 1.26 업그레이드 이후, Node Plane 업그레이드 진행필요 ~ base.tf
#
cat base.tf
...
eks_managed_node_group_defaults = {
cluster_version = var.mng_cluster_version
}
eks_managed_node_groups = { # 버전 명시가 없으면, 상단 default 버전 사용 -> variables.tf 확인
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
update_config = {
max_unavailable_percentage = 35
}
}
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]]
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}

관리 노드 그룹 업데이트를 수행할 때 다음 시나리오를 보여드리겠습니다.
- 특정 AMI ID 사용(사용자 정의 AMI와 같음) Using specific AMI ID (like custom AMIs)
- 지정된 K8s 버전에 대한 기본 AMI 사용 Using default AMI for given K8s version
☞ 이 실험실의 전제 조건으로 먼저 사용자 지정 AMI를 사용하여 신규 관리 노드 그룹을 생성해 보겠습니다.
이를 위해 kubernetes 버전 1.25의 ami_id를 가져오고 variable.tf 파일의 변수 ami_id를 결과 값으로 대체해 보겠습니다.
#
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Blueprint,Values=eksworkshop-eksctl" --output table
#
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE LIFECYCLE CAPACITY-TYPE COMPUTE-TYPE
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-2d5f260 fargate
ip-10-0-12-228.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 self-managed
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 spot
ip-10-0-44-106.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 ON_DEMAND
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 self-managed
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
NAME STATUS ROLES AGE VERSION NODEGROUP NODEPOOL
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-2d5f260
ip-10-0-12-228.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 initial-2025032502302076080000002c
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 blue-mng-20250325023020754500000029
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 default
ip-10-0-44-106.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375 initial-2025032502302076080000002c
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 12h v1.25.16-eks-59bf375
#
kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami
ip-10-0-13-217.us-west-2.compute.internal Ready <none> 26h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-3-168.us-west-2.compute.internal Ready <none> 26h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-42-84.us-west-2.compute.internal Ready <none> 26h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
# 1.25 AMI 확인 !!
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.25/amazon-linux-2/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text
ami-0078a0f78fafda978
아래와 같이 variable.tf 파일에서 ami_id를 업데이트합니다.


☞ base.tf사용자 정의 관리 노드 그룹을 프로비저닝하려면 다음 코드를 추가한다.
custom = {
instance_types = ["t3.medium"]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
ami_id = try(var.ami_id)
enable_bootstrap_user_data = true
}
☞ Terraform Plan을 실행하고 적용합니다.

# 모니터링
aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq
kubectl get node -L eks.amazonaws.com/nodegroup
kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
# 2분 정도 소요
terraform plan && terraform apply -auto-approve
#
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
NAME STATUS ROLES AGE VERSION NODEGROUP
ip-10-0-44-132.us-west-2.compute.internal Ready <none> 78s v1.25.16-eks-59bf375 custom-20250325154855579500000007
NAME STATUS ROLES AGE VERSION NODEGROUP-IMAGE
ip-10-0-44-132.us-west-2.compute.internal Ready <none> 79s v1.25.16-eks-59bf375 ami-0078a0f78fafda978
[
"default-selfmng-2025032502302075740000002b",
"eks-blue-mng-20250325023020754500000029-00cae591-7abe-6143-dd33-c720df2700b6",
"eks-custom-20250325154855579500000007-bccae6ff-0a65-c291-f471-404701dd84a8",
"eks-initial-2025032502302076080000002c-30cae591-7ac2-1e9c-2415-19975314b08b"
]
#
kubectl describe node ip-10-0-44-132.us-west-2.compute.internal
...
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=t3.medium
beta.kubernetes.io/os=linux
eks.amazonaws.com/capacityType=ON_DEMAND
eks.amazonaws.com/nodegroup=custom-20250325154855579500000007
eks.amazonaws.com/nodegroup-image=ami-0078a0f78fafda978
eks.amazonaws.com/sourceLaunchTemplateId=lt-0db2ddc3fdfb0afb1
eks.amazonaws.com/sourceLaunchTemplateVersion=1
...
kubectl get pod -A -owide | grep 10-0-44-132
kube-system aws-node-tt4lp 2/2 Running 0 4m20s 10.0.44.132 ip-10-0-44-132.us-west-2.compute.internal <none> <none>
kube-system ebs-csi-node-msbmj 3/3 Running 0 4m20s 10.0.39.97 ip-10-0-44-132.us-west-2.compute.internal <none> <none>
kube-system efs-csi-node-cb58m 3/3 Running 0 4m20s 10.0.44.132 ip-10-0-44-132.us-west-2.compute.internal <none> <none>
kube-system kube-proxy-7ddnw 1/1 Running 0 4m20s 10.0.44.132 ip-10-0-44-132.us-west-2.compute.internal <none> <none>

초기 관리 노드그룹에는 정의된 클러스터 버전이 없으며 기본적으로 eks_managed_node_group_defaults에 정의된 클러스터 버전을 사용하도록 설정됩니다.
eks_managed_node_group_defaults 클러스터_버전의 값은 variable.tf 의 변수 mng_cluster_version에 정의되어 있습니다.
☞ variable.tf 에서 변수 mng_cluster_version을 "1.25"에서 "1.26"으로 변경하고 테라폼을 실행하면 됩니다.

#
terraform plan -no-color > plan-output.txt
# plan-output.txt 내용 확인
# module.eks.module.eks_managed_node_group["initial"].aws_eks_node_group.this[0] will be updated in-place
~ resource "aws_eks_node_group" "this" {
id = "eksworkshop-eksctl:initial-2025032502302076080000002c"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
"Name" = "initial"
"karpenter.sh/discovery" = "eksworkshop-eksctl"
}
~ version = "1.25" -> "1.26"
...
이 계획에 따라 initial managed node group은 1.26 버전으로 업그레이드되지만, custom managed nodegroup 을 프로비저닝하는 동안 특정 AMI를 정의했기 때문에 업그레이드 되지 않습니다.
따라서 커스텀 관리 노드 그룹과 같이 커스텀 AMI로 구성된 관리 노드 그룹이 있는 경우 업그레이드된 Kubernetes 버전에 커스텀 AMI를 제공하여 관리 노드 그룹을 업그레이드할 수 있습니다.
Lets upgrade the initial and custom managed node groups to latest cluster version.
kubernetes 버전 1.26에 대해 ami_id를 검색한 후 variable.tf 에서 다음과 같은 변경 사항을 적용합니다.
## 1.26 AMI 확인 : ami-086414611b43bb691
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text
☞ mng_cluster_version 변수를 에서 . 1.25 -> 1.26 으로 변경합니다.
ami_id 변수를 ami-0078a0f78fafda978에서 ami-086414611b43bb691로 변경합니다.
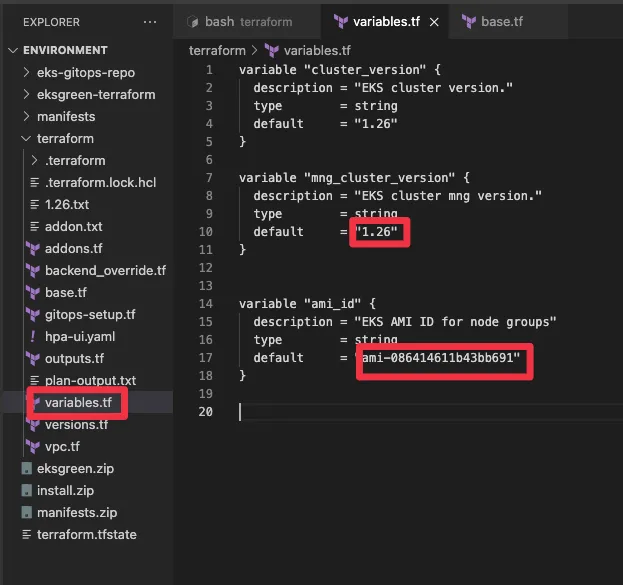
☞ Terraform 계획을 실행하고 적용


# 모니터링
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
...
ip-10-0-10-86.us-west-2.compute.internal Ready <none> 95s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-13-217.us-west-2.compute.internal Ready,SchedulingDisabled <none> 26h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-17-199.us-west-2.compute.internal Ready <none> 3m41s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-19-132.us-west-2.compute.internal Ready <none> 5m53s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-2-59.us-west-2.compute.internal Ready,SchedulingDisabled <none> 22m v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-26-240.us-west-2.compute.internal Ready <none> 4m46s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-29-245.us-west-2.compute.internal Ready <none> 5m51s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-3-168.us-west-2.compute.internal Ready <none> 26h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-33-7.us-west-2.compute.internal Ready <none> 4m56s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-40-197.us-west-2.compute.internal Ready <none> 2m45s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-41-92.us-west-2.compute.internal Ready <none> 5m54s v1.26.15-eks-59bf375 ami-086414611b43bb691
ip-10-0-42-84.us-west-2.compute.internal Ready,SchedulingDisabled <none> 26h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-9-129.us-west-2.compute.internal Ready <none> 3m47s v1.26.15-eks-59bf375 ami-086414611b43bb691
...
...
ip-10-0-2-59.us-west-2.compute.internal NotReady,SchedulingDisabled <none> 23m v1.25.16-eks-59bf375 ami-0078a0f78fafda978
...
# 20분 소요 : UI 웹과 liveness 반복 접속도 해보자, 노드에 labels 와 taint 변화도 모니터링 해보자.
terraform plan && terraform apply -auto-approve
...
완료되면 Amazon EKS 콘솔에서 initial and custom manage node groups의 변경 사항을 확인할 수 있습니다.
초기 및 맞춤형 관리 노드그룹 kubernetes 버전이 1.26임을 알 수 있습니다.


custom 은 실습 동작 확인했으니, 다음 실습을 위해서 제거하자.
다음 변경 사항을 적용 base.tf하고 terraform plan과 terraform apply를 실행합니다.

terraform plan && terraform apply -auto-approve
Step2. Blue Green approach for Managed Node group Upgrade* 10분 소요 실습 포함
이전 실습에서 Blue-mng 에 대한 업그레이드는 아직 진행되지 않았습니다.
Blue-mng 관리 노드 그룹의 구성을 보면, 이 노드 그룹에 할당된 노드들이 특정 테인트와 라벨을 가지고 있으며**, 하나의 특정 가용성 구역에 할당**되도록 구성되어 있음을 알 수 있습니다.
Here we have followed the recommended best practice to provision managed node group for stateful workloads, i.e.
상태 저장 워크로드를 위한 관리 노드 그룹은 가용 영역(AZ)별로 프로비저닝되어야 합니다.
Managed node groups for stateful workloads should be provisioned per availability zone (AZ).
이 실험실에서는 stateful 워크로드의 마이그레이션을 시연하고 있습니다.
Blue-mng 관리 노드 그룹의 노드에서 실행되는 my-sql 포드로 구성된 Orders 애플리케이션 포드가 있습니다.
우리는 blue-mng와 유사한 구성을 가진 새로운 관리 노드 그룹 green-mng을 만들 것입니다.
Green-mng는 eks_managed_node_group_defaults에 제공된 클러스터 버전(즉, 1.26)과 Blue-mng과 동일한 가용성 영역에서 프로비저닝됩니다.
그 후에, 우리는 blue-mng을 삭제할 것입니다.
블루밍 노드가 자동으로 코드화되고 배수되며, 주문 앱 포드가 그린밍에서 프로비저닝되는 것을 볼 수 있습니다.
It will automatically cordoned and drained blue-mng nodes and we will see orders app pods will get provisioned on green-mng.
☞ base.tf 에서 blue-mng 그룹을 찾아서 확인한다.
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]] # 해당 MNG은 프라이빗서브넷1 에서 동작(ebs pv 사용 중)
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
#
terraform state show 'module.vpc.aws_subnet.private[0]'
terraform state show 'module.vpc.aws_subnet.private[1]'
terraform state show 'modle.vpc.aws_subnet.private[2]'
☞ Lets get the node provisioned for this node group.
#
kubectl get nodes -l type=OrdersMNG
NAME STATUS ROLES AGE VERSION
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 21h v1.25.16-eks-59bf375
# Check if the node have specific taints applied to it.
kubectl get nodes -l type=OrdersMNG -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
ip-10-0-3-199.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"OrdersApp"}
# Check which pods are running on this node.
# Non-terminated Pods: in above output, kube-system pods and orders app pods running on this node.
kubectl describe node -l type=OrdersMNG
...
Labels: beta.kubernetes.io/arch=amd64
...
type=OrdersMNG
Taints: dedicated=OrdersApp:NoSchedule
...
Non-terminated Pods: (6 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system aws-node-pnx48 50m (2%) 0 (0%) 0 (0%) 0 (0%) 21h
kube-system ebs-csi-node-qqmsh 30m (1%) 0 (0%) 120Mi (1%) 768Mi (11%) 21h
kube-system efs-csi-node-rcggq 0 (0%) 0 (0%) 0 (0%) 0 (0%) 21h
kube-system kube-proxy-kxvh5 100m (5%) 0 (0%) 0 (0%) 0 (0%) 9h
orders orders-5b97745747-mxg72 250m (12%) 0 (0%) 1Gi (14%) 1Gi (14%) 21h
orders orders-mysql-b9b997d9d-hdt9m 0 (0%) 0 (0%) 0 (0%) 0 (0%) 15h
...
#
kubectl get pvc -n orders
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
order-mysql-pvc Bound pvc-875d1ca7-e28b-421a-8a7e-2ae9d7480b9a 4Gi RWO gp3 21h
#
cat eks-gitops-repo/apps/orders/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: orders
...
spec:
nodeSelector:
type: OrdersMNG
tolerations:
- key: "dedicated"
operator: "Equal"
value: "OrdersApp"
effect: "NoSchedule"
cat eks-gitops-repo/apps/orders/deployment-mysql.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: orders-mysql
...
spec:
nodeSelector:
type: OrdersMNG
tolerations:
- key: "dedicated"
operator: "Equal"
value: "OrdersApp"
effect: "NoSchedule"
☞ Now Lets create a new managed node group green-mng by adding below code in base.tf file under eks module, eks_managed_node_groups
( Green -그룹 생성 )
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]]
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
green-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
subnet_ids = [module.vpc.private_subnets[0]]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
}
☞ We have made following changes in base.tf file. Run terraform plan and apply after making the changes

# 모니터링
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
# 3분 소요
terraform plan && terraform apply -auto-approve
☞ You will see green-mng will be created with latest control plane version in Amazon EKS console .
# Lets get the nodes with labels type=OrdersMNG.
kubectl get node -l type=OrdersMNG -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 2m25s v1.26.15-eks-59bf375 10.0.10.196 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 21h v1.25.16-eks-59bf375 10.0.3.199 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
kubectl get node -l type=OrdersMNG -L topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION ZONE
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 3m21s v1.26.15-eks-59bf375 us-west-2a
ip-10-0-3-199.us-west-2.compute.internal Ready <none> 21h v1.25.16-eks-59bf375 us-west-2a
# Check if this node have same taints applied to it.
kubectl get nodes -l type=OrdersMNG -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
ip-10-0-10-196.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"OrdersApp"}
ip-10-0-3-199.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"OrdersApp"}
동일한 레이블과 테인트를 가진 두 개의 노드가 있습니다. 블루-mng 관리 노드 그룹 노드는 버전 v1.25.16-eks-ae9a62a에 있고 그린-mng 관리 노드 그룹 노드는 버전 v1.26.15-eks-ae9a62a에 있습니다.

# Blue-mng과 Green-mng 관리 그룹 이름을 각각 BLUE_MNG 변수와 GREEN_MNG 변수로 내보냅니다.
export BLUE_MNG=$(aws eks list-nodegroups --cluster-name eksworkshop-eksctl | jq -c .[] | jq -r 'to_entries[] | select( .value| test("blue-mng*")) | .value')
echo $BLUE_MNG
blue-mng-20250325023020754500000029
export GREEN_MNG=$(aws eks list-nodegroups --cluster-name eksworkshop-eksctl | jq -c .[] | jq -r 'to_entries[] | select( .value| test("green-mng*")) | .value')
echo $GREEN_MNG
green-mng-20250325235742179300000007
Blue-mng 관리 노드 그룹을 삭제합니다. It will automatically cordon and drain the blue managed node group nodes and orders app pods will get scheduled on to green managed node group nodes.
클러스터 업그레이드 준비 실험실에서 주문 시 PodDisruptionBudget(PDB)을 생성했다면, 배포가 1개의 복제본으로 설정되고 PDB가 minAvailable=1로 설정될 때 노드 그룹 삭제 프로세스가 차단됩니다. 따라서 이 문제를 해결하기 위해 복제본을 2개로 늘립니다.
#
kubectl get pdb -n orders
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
#
cd ~/environment/eks-gitops-repo/
sed -i 's/replicas: 1/replicas: 2/' apps/orders/deployment.yaml
git add apps/orders/deployment.yaml
git commit -m "Increase orders replicas 2"
git push
# sync 를 해도 HPA로 무시로 인해 파드는 1개 유지 상태
argocd app sync orders
# apps 설정에 deploy replicas 무시 설정되어 있으니, 아래처럼 직접 증가해둘것 (이미 위에서 코드상에는 2로 변경)
# (실행 과정 중) orders 파드가 다른 노드로 옮겨감.. 실행 전에 replicas=2로 실행해두어서 좀 더 안정성 확보
kubectl scale deploy -n orders orders --replicas 2
#
kubectl get deploy -n orders
kubectl get pod -n orders


#
kubectl get node -l type=OrdersMNG
kubectl get pod -n orders -l app.kubernetes.io/component=service -owide
kubectl get deploy -n orders orders
kubectl get pdb -n orders
aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq
while true; do kubectl get node -l type=OrdersMNG; echo ; kubectl get pod -n orders -l app.kubernetes.io/component=service -owide ; echo ; kubectl get deploy -n orders orders; echo ; kubectl get pdb -n orders; echo ; aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; date ; done
# 10분 정도 소요
cd ~/environment/terraform/
terraform plan && terraform apply -auto-approve
# 신규(버전) 노드 확인
kubectl get node -l eks.amazonaws.com/nodegroup=$GREEN_MNG
NAME STATUS ROLES AGE VERSION
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 45m v1.26.15-eks-59bf375
aws eks list-nodegroups --cluster-name eksworkshop-eksctl
{
"nodegroups": [
"green-mng-20250325235742179300000007",
"initial-2025032502302076080000002c"
]
}
# 기존 노드 스케줄 중지
Wed Mar 26 00:32:43 UTC 2025
NAME STATUS ROLES AGE VERSION
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 33m v1.26.15-eks-59bf375
ip-10-0-3-199.us-west-2.compute.internal Ready,SchedulingDisabled <none> 22h v1.25.16-eks-59bf375
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
orders-5b97745747-mxg72 1/1 Running 2 (21h ago) 21h 10.0.5.219 ip-10-0-3-199.us-west-2.compute.internal <none> <none>
NAME READY UP-TO-DATE AVAILABLE AGE
orders 1/1 1 1 21h
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
# orders 파드가 다른 노드로 옮겨감.. 실행 전에 replicas=2로 실행해두었으면 더 좋았을듯..
## kubectl scale deploy -n orders orders --replicas 1
Wed Mar 26 00:32:47 UTC 2025
NAME STATUS ROLES AGE VERSION
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 34m v1.26.15-eks-59bf375
ip-10-0-3-199.us-west-2.compute.internal Ready,SchedulingDisabled <none> 22h v1.25.16-eks-59bf375
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
orders-5b97745747-wr9bf 0/1 ContainerCreating 0 2s <none> ip-10-0-10-196.us-west-2.compute.internal <none> <none>
NAME READY UP-TO-DATE AVAILABLE AGE
orders 0/1 1 0 21h
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
# 신규 노드로 옮겨간 orders 파드가 정상 상태가 되자, 기존 노드는 종료 실행으로 NotReady 상태
Wed Mar 26 00:33:28 UTC 2025
NAME STATUS ROLES AGE VERSION
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 34m v1.26.15-eks-59bf375
ip-10-0-3-199.us-west-2.compute.internal NotReady,SchedulingDisabled <none> 22h v1.25.16-eks-59bf375
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
orders-5b97745747-wr9bf 1/1 Running 0 44s 10.0.8.253 ip-10-0-10-196.us-west-2.compute.internal <none> <none>
NAME READY UP-TO-DATE AVAILABLE AGE
orders 1/1 1 1 21h
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
# 기존 노드 그룹 삭제됨
Wed Mar 26 00:33:34 UTC 2025
NAME STATUS ROLES AGE VERSION
ip-10-0-10-196.us-west-2.compute.internal Ready <none> 34m v1.26.15-eks-59bf375
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
orders-5b97745747-wr9bf 1/1 Running 0 50s 10.0.8.253 ip-10-0-10-196.us-west-2.compute.internal <none> <none>
NAME READY UP-TO-DATE AVAILABLE AGE
orders 1/1 1 1 21h
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
[
"default-selfmng-2025032502302075740000002b",
"eks-green-mng-20250325235742179300000007-8acae7de-c8e8-3c1d-f093-acddb3156142",
"eks-initial-2025032502302076080000002c-30cae591-7ac2-1e9c-2415-19975314b08b"
]
# 이벤트 로그 확인
kubectl get events --sort-by='.lastTimestamp' --watch
4m55s Normal NodeNotSchedulable node/ip-10-0-3-199.us-west-2.compute.internal Node ip-10-0-3-199.us-west-2.compute.internal status is now: NodeNotSchedulable
0s Normal NodeNotReady node/ip-10-0-3-199.us-west-2.compute.internal Node ip-10-0-3-199.us-west-2.compute.internal status is now: NodeNotReady
0s Normal DeletingNode node/ip-10-0-3-199.us-west-2.compute.internal Deleting node ip-10-0-3-199.us-west-2.compute.internal because it does not exist in the cloud provider
0s Normal RemovingNode node/ip-10-0-3-199.us-west-2.compute.internal Node ip-10-0-3-199.us-west-2.compute.internal event: Removing Node ip-10-0-3-199.us-west-2.compute.internal from Controller
이 Lab 에서는 1.26 EKS AMI를 가진 새로운 그린-mng 관리 노드 그룹을 생성하고 기존 블루-mng 노드 그룹을 삭제하여 포드를 새로운 노드 그룹으로 이동시켰습니다. EKS 관리 노드 그룹 서비스는 자동으로 노드를 코드화하고 배수하며, 포드 중단 예산을 사용하여 애플리케이션 다운타임을 최소화했습니다.
In this lab, we started with creating a new green-mng managed node group with 1.26 EKS AMI and deleted existing blue-mng node group to move the pods to the new node group. EKS Managed node group service automatically cordoned and drained the nodes and Pod Disruption Budgets are used to minimize the application downtime.


(옵션) 혹시 catalog-mysql-0 파드(EBS PVC)가 배포된 노드들의 AZ와 맞지 않을 경우, 그냥 임시로 ASG를 3대로 늘려서 해결해두자.
Step3-2. Data-Plane Upgrade [ Karpenter Node-group ]
Karpenter는 집계된 CPU, 메모리, 볼륨 요청 및 기타 Kubernetes 스케줄링 제약(예: 친화도 및 포드 토폴로지 확산 제약)을 기반으로 스케줄링 불가능한 포드에 대응하여 적절한 크기의 노드를 제공하는 오픈 소스 클러스터 오토스케일러로, 인프라 관리를 간소화합니다.
또한 Karpenter는 노드 그룹 및 Amazon EC2 자동 확장 그룹과 같은 외부 인프라와 용량 관리를 조정하지 않기 때문에 운영 프로세스에 대한 다른 관점을 도입하여 작업자 노드 구성 요소와 운영 체제를 최신 보안 패치 및 기능으로 최신 상태로 유지합니다.
AWS는 새로운 Kubernetes 버전뿐만 아니라 패치 및 CVE(일반 취약점 및 노출)를 위한 AMI를 출시합니다. 다양한 Amazon EKS에 최적화된 AMI 중에서 선택할 수 있습니다. 또는 자신만의 맞춤형 AMI를 사용할 수도 있습니다.
현재 Karpenter에서는 EC2NodeClass 리소스가 amiFamily 값 AL2, AL2023, Bottlerocket, Ubuntu, Windows2019, Windows2022 및 Custom을 지원합니다. amiFamily of Custom을 선택하면 어떤 사용자 지정 AMI를 사용할지 Karpenter에 알려주는 amiSelectorTerms를 지정해야 합니다.
Karpenter는 Karpenter를 통해 프로비저닝된 Kubernetes 작업자 노드를 패치하는 데 Drift 또는 타이머(expireAfter)와 같은 기능을 사용합니다.
1. Drift
Karpenter는 롤링 배포 후 Drift를 사용하여 Kubernetes 노드를 업그레이드합니다.
Karpenter를 통해 프로비저닝된 Kubernetes 노드가 원하는 사양에서 벗어난 경우, Karpenter는 먼저 새로운 노드를 프로비저닝하고 이전 노드에서 포드를 제거한 다음 종료합니다.
노드가 디프로비전됨에 따라 노드는 새로운 포드 스케줄링을 방지하기 위해 코드화되고 Kubernetes Eviction API를 사용하여 포드가 퇴거됩니다.
EC2NodeClass에서는 amiFamily가 필수 필드이며, 자신의 AMI 값인 EKS 최적화 AMI를 사용할 수 있습니다.
AMI의 드리프트는 두 가지 동작이 있으며, 아래에 자세히 설명되어 있습니다.
1) Drift with specified AMI values 지정된 AMI 값을 사용한 드리프트:
EC2NodeClass에서 NodePool의 AMI를 변경하거나 다른 EC2NodeClass를 NodePool과 연결하면, Karpenter는 기존 작업자 노드가 원하는 설정에서 벗어났음을 감지합니다.여러 AMI가 기준을 충족하면 최신 AMI가 선택됩니다.상태를 얻는 한 가지 방법은 EC2NodeClass에서 kubectl 설명을 실행하는 것입니다. 특정 시나리오에서는 EC2NodeClass에 의해 이전 AMI와 새로운 AMI가 모두 발견되면, 이전 AMI를 가진 실행 중인 노드들이 드리프트되고, 디프로비전되며, 새로운 AMI를 가진 작업자 노드로 대체됩니다. 새로운 노드들은 새로운 AMI를 사용하여 프로비저닝됩니다.
- 고객은 EC2NodeClass의 상태 필드에 있는 AMI 값에서 EC2NodeClass가 발견한 AMI를 추적할 수 있습니다.
- AMI는 AMI ID, AMI 이름 또는 amiSelectorTerms를 사용하여 특정 태그로 명시적으로 지정할 수 있습니다.
- 일관성을 위해 애플리케이션 환경을 통해 AMI의 promotion를 제어하는 이 접근 방식을 고려할 수 있습니다.
kubectl get EC2NodeClass default -o jsonpath={.status.amis} | jq
[
{
"id": "ami-0ee947a6f4880da75",
"name": "amazon-eks-node-1.25-v20250123",
...
2) Drift with Amazon EKS optimized AMIs Amazon EKS 최적화 AMI를 사용한 드리프트:
AMiFamily 필드에 AL2, AL2023, Bottlerocket, Ubuntu, Windows2019 또는 Windows2022의 값을 지정하여 Karpenter에 어떤 Amazon EKS에 최적화된 AMI를 사용해야 하는지 알려줄 수 있습니다.이러한 노드는 프로비저닝이 해제되고 최신 AMI를 가진 작업자 노드로 대체됩니다. 이 접근 방식을 사용하면 이전 AMI를 가진 노드는 자동으로 재활용됩니다(예: 새로운 AMI가 있을 때 또는 Kubernetes 제어 평면 업그레이드 후).
- 이전 접근 방식인 amiSelectorTerms를 사용하면 노드가 업그레이드될 때 더 많은 제어 권한을 가질 수 있습니다.
- Karpenter는 실행 중인 EKS 버전 클러스터를 위해 지정된 최신 Amazon EKS 최적화 AMI로 노드를 프로비저닝합니다. Karpenter는 Kubernetes 클러스터 버전의 새로운 AMI가 언제 출시되는지 감지하고 기존 노드를 드리프트합니다. 상태 필드에서 EC2NodeClass AMI 값은 새로 발견된 AMI를 반영합니다.
- EC2NodeClass에 amiSelectorTerms가 지정되지 않은 경우, Karpenter는 Amazon EKS에 최적화된 AMI에 대해 게시된 SSM 매개변수를 모니터링합니다.
2. TTL (expireAfter) to automatically delete nodes from the cluster 클러스터에서 노드를 자동으로 삭제
프로비저닝된 노드에서 ttl을 사용하여 워크로드 포드가 없거나 만료 시간에 도달한 노드를 삭제할 시기를 설정할 수 있습니다. 노드 만료는 업그레이드 수단으로 사용할 수 있으므로 노드가 폐기되고 업데이트된 버전으로 대체될 수 있습니다.
Karpenter는 NodePool의 spec.druption.expireAfter 값에 따라 노드가 만료된 것으로 표시하고 설정된 시간(초)이 지나면 노드를 중단합니다.
보안 문제로 인해 노드 만료를 사용하여 주기적으로 노드를 재활용할 수 있습니다.
kubectl get nodepools default -o jsonpath={.spec.disruption} | jq
{
"budgets": [
{
"nodes": "10%"
}
],
"consolidationPolicy": "WhenUnderutilized",
"expireAfter": "Never"
}
3. Disruption Budgets
이러한 karpenter 중단을 제어하려는 특정 시나리오가 있습니다. 예를 들어:
- 미션 크리티컬 워크로드를 실행 중인데 자발적인 중단으로 인해 노드를 재활용하고 싶지 않을 때.
- 100개의 드리프트 또는 만료가 한 번에 정렬되어 모든 활성 노드를 함께 회전하는 시나리오의 경우. 이러한 시나리오에서는 중단되는 활성 노드의 수와 중단 시점을 제어해야 합니다.
우리는 NodePool의 spec.disruption.budgets를 통해 Karpenter disruption 를 rate limit 할 수 있습니다.
Disruption Budgets 을 사용하면 새로운 AMI를 가진 노드로의 업그레이드 속도를 늦추거나(일정을 사용하여) 선택된 날짜와 시간 동안에만 업그레이드가 이루어지도록 할 수 있습니다.
이렇게 하면 나쁜 AMI가 배포되는 것을 방지할 수는 없지만, 노드가 업그레이드되는 시기를 제어할 수 있지만, 롤아웃 문제에 더 많은 시간을 대응할 수 있습니다.
Disruption Budgets은 노드가 중단될 수 있는 시기와 정도를 제한합니다. 노드(한 번에 중단될 수 있는 노드의 비율 또는 수)와 일정(노드 중단으로 인한 특정 시간 제외)에 따라 중단을 방지할 수 있습니다.
정의되지 않으면 Karpenter는 노드가 있는 **budgets 10%**로 기본 설정됩니다.
budgets은 어떤 이유로든 적극적으로 삭제되는 노드를 고려하며, 만료, 드리프트, 공백 및 통합을 통해 자발적으로 노드를 방해하지 못하도록 Karpenter를 차단합니다.
예시)
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec: # This is not a complete NodePool Spec.
disruption:
consolidationPolicy: WhenEmpty
expireAfter: 720h # 30 * 24h = 720h
budgets:
- nodes: 0이 budgets으로 카르펜터는 이 노드풀을 통해 프로비저닝된 노드가 자발적인 중단으로 간주되는 것을 방지할 수 있습니다.
This budget allow karpenter to disrupt active nodes one at a time. 한번에 1대씩 노드만 중단
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec: # This is not a complete NodePool Spec.
disruption:
consolidationPolicy: WhenEmpty
expireAfter: 720h # 30 * 24h = 720h
budgets:
- nodes: "1"
이러한 예산으로 인해 카르펜터는 평일 영업 시간 동안 노드의 프로비저닝을 해제할 수 없습니다. 그외 시간에 10개의 노드만 동시에 프로비저닝을 해제할 수 있습니다
With these budgets, karpenter is not allowed to de-provision any node on weekdays during business hours. Every other time, only allow 10 nodes to be de-provisioned simultaneously
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec: # This is not a complete NodePool Spec.
disruption:
consolidationPolicy: WhenEmpty
expireAfter: 720h # 30 * 24h = 720h
budgets:
- schedule: "0 9 * * mon-fri"
duration: 8h
nodes: 0
- nodes: 10As prerequisite for this lab, lets clone codecommit repo eks-gitops-rep (if you haven't already)
git clone codecommit::${REGION}://eks-gitops-repo
cd eks-gitops-repo# In this lab, we have already installed karpenter and applied default NodePool and EC2NodeClass on the cluster.
kubectl describe nodepool
Name: default
Namespace:
Labels: argocd.argoproj.io/instance=karpenter
Annotations: karpenter.sh/nodepool-hash: 12028663807258658692
karpenter.sh/nodepool-hash-version: v2
API Version: karpenter.sh/v1beta1
Kind: NodePool
Metadata:
Creation Timestamp: 2025-03-25T02:40:15Z
Generation: 1
Resource Version: 6130
UID: 7e081e92-bcfb-4e88-a611-026349b02dd9
Spec:
Disruption:
Budgets:
Nodes: 10%
Consolidation Policy: WhenUnderutilized
Expire After: Never
Limits:
Cpu: 100
Template:
Metadata:
Labels:
Env: dev
Team: checkout
Spec:
Node Class Ref:
Name: default
Requirements:
Key: karpenter.k8s.aws/instance-family
Operator: In
Values:
c5
m5
m6i
m6a
r4
c4
Key: kubernetes.io/arch
Operator: In
Values:
amd64
Key: karpenter.sh/capacity-type
Operator: In
Values:
on-demand
spot
Key: kubernetes.io/os
Operator: In
Values:
linux
Taints:
Effect: NoSchedule
Key: dedicated
Value: CheckoutApp
Status:
Resources:
Attachable - Volumes - Aws - Ebs: 25
Cpu: 4
Ephemeral - Storage: 20959212Ki
Memory: 7766420Ki
Pods: 58
Events: <none>kubectl describe ec2nodeclass
Name: default
Namespace:
Labels: argocd.argoproj.io/instance=karpenter
Annotations: karpenter.k8s.aws/ec2nodeclass-hash: 5256777658067331158
karpenter.k8s.aws/ec2nodeclass-hash-version: v2
API Version: karpenter.k8s.aws/v1beta1
Kind: EC2NodeClass
Metadata:
Creation Timestamp: 2025-03-25T02:40:15Z
Finalizers:
karpenter.k8s.aws/termination
Generation: 1
Resource Version: 531983
UID: 1dc1bfc4-adfe-4889-84c5-05d57c7e768d
Spec:
Ami Family: AL2
Ami Selector Terms:
Id: ami-0ee947a6f4880da75
Metadata Options:
Http Endpoint: enabled
httpProtocolIPv6: disabled
Http Put Response Hop Limit: 2
Http Tokens: required
Role: karpenter-eksworkshop-eksctl
Security Group Selector Terms:
Tags:
karpenter.sh/discovery: eksworkshop-eksctl
Subnet Selector Terms:
Tags:
karpenter.sh/discovery: eksworkshop-eksctl
Tags:
Intent: apps
Managed - By: karpenter
Team: checkout
Status:
Amis:
Id: ami-0ee947a6f4880da75
Name: amazon-eks-node-1.25-v20250123
Requirements:
Key: kubernetes.io/arch
Operator: In
Values:
amd64
Conditions:
Last Transition Time: 2025-03-25T02:40:16Z
Message:
Reason: Ready
Status: True
Type: Ready
Instance Profile: eksworkshop-eksctl_4067990795380418201
Security Groups:
Id: sg-009b495bdf238c9dd
Name: eksworkshop-eksctl-node-2025032502202294260000000c
Id: sg-09f8b41af6cadd619
Name: eks-cluster-sg-eksworkshop-eksctl-1769733817
Id: sg-0ef166af090e168d5
Name: eksworkshop-eksctl-cluster-2025032502202287160000000b
Subnets:
Id: subnet-047ab61ad85c50486
Zone: us-west-2b
Zone ID: usw2-az1
Id: subnet-01bbd11a892aec6ee
Zone: us-west-2a
Zone ID: usw2-az2
Id: subnet-0aeb12f673d69f7c5
Zone: us-west-2c
Zone ID: usw2-az3
Events: <none>기본 노드풀 및 ec2 nod 클래스의 출력에서 다음을 확인할 수 있습니다:
- 이 노드풀을 사용하면 Spec.Druption.Budgets에 따라 중단 시 10% 노드가 재활용되는 기본 예산이 적용됩니다.
- 이 노드풀에 대해 카르펜터를 통해 프로비저닝된 노드에는 Team: 체크아웃 라벨이 Spec.Template.Metadata.Labels에 따라 표시되며, 이들 노드에는 Spec.Template.Spec.Taints에 따라 태그가 적용됩니다.
- 이 노드풀은 Spec.Template.Spec.NodeClass Ref에 따라 기본 EC2NodeClass를 사용하고 있습니다.
- 이 기본 EC2NodeClass 사양을 사용하여 노드풀은 아미드 ami-03db5eb 228232c943을 사용하여 노드를 프로비저닝하고 있습니다.
node selector label team=checkou와 default nodepool을 통해 프로비저닝된 노드에 tolerations to tolerate taints를 가진 체크아웃 앱 포드를 프로비저닝했습니다.
Checkout 앱은 포드에 지속적인 볼륨이 부착된 stateful 애플리케이션입니다.
이 실험실에서는 상태 저장 워크로드를 실행하는 카펜터를 통해 프로비저닝된 노드를 업그레이드하는 방법을 시연할 것입니다.
이를 위해 kubernetes 버전 1.26용으로 빌드된 AMI ID를 가진 eks-gitops-repo/apps/karpenter 폴더의 기본 eks-ec2nc.yaml 파일에서 AMI ID를 변경하고 eks-gitops-repo의 변경 사항을 푸시할 것입니다.
Argo-CD를 통해 변경 사항이 동기화되면 Karpenter 컨트롤러는 노드가 드리프트되었음을 자동으로 감지하여 드리프트된 노드를 최신 구성의 노드로 프로비저닝하는 데 방해가 될 것입니다.
논의한 바와 같이, 중단되는 노드의 수를 제어하거나 특정 시간에만 노드를 중단시키는 시나리오가 있습니다.
이 실험실에서는 Karpenter가 다른 노드를 프로비저닝하여 예정에 없던 체크아웃 포드를 실행할 수 있도록 체크아웃 앱을 확장할 것입니다. 그
런 다음 한 번에 하나씩 노드를 중단시키기 위한 중단 예산을 정의합니다.
Karpenter 컨트롤러는 한 번에 하나씩 드리프트를 통해 노드를 중단합니다.
☞ 이 노드풀에 대해 카펜터를 통해 노드를 프로비저닝해 보겠습니다
# Taints 확인
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Blueprint,Values=eksworkshop-eksctl" --output table
# 기본 노드풀을 통해 프로비저닝된 노드가 버전 v1.25.16-eks-59bf375에 있는 것을 확인할 수 있습니다.
kubectl get nodes -l team=checkout
NAME STATUS ROLES AGE VERSION
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 24h v1.25.16-eks-59bf375
# Check taints applied on the nodes.
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
ip-10-0-39-95.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}
#
kubectl get pods -n checkout -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-fs8dk 1/1 Running 0 24h 10.0.39.105 ip-10-0-39-95.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-whk4r 1/1 Running 0 24h 10.0.41.7 ip-10-0-39-95.us-west-2.compute.internal <none> <none>
# 모니터링
kubectl get nodeclaim
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"
kubectl get pods -n checkout -o wide
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
- 결제 앱 포드가 카펜터(Karpenter)에서 프로비저닝한 노드에서 실행되고 있는 것을 볼 수 있습니다.
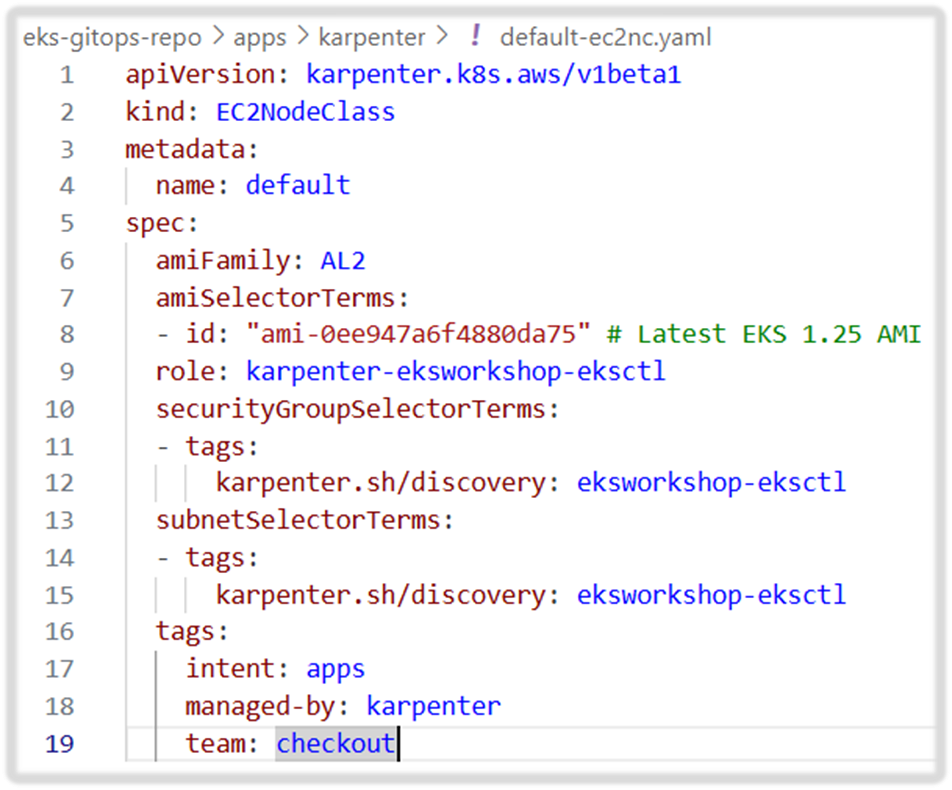

☞ 체크아웃 애플리케이션을 확장해 보겠습니다. 이를 위해 아래와 같이 eks-gitops-repo/apps/checkout 폴더의 deployment.yaml 파일에서 복제본을 1에서 10으로 변경합니다.


☞ 변경이 완료되면 저장소에 변경 사항을 커밋하고 푸시한 후 Argo-cd가 변경 사항을 동기화할 때까지 기다립니다.
#
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
#
cd ~/environment/eks-gitops-repo
git add apps/checkout/deployment.yaml
git commit -m "scale checkout app"
git push --set-upstream origin main
# You can force the sync using ArgoCD console or following command:
argocd app sync checkout
# LIVE(k8s)에 직접 scale 실행
kubectl scale deploy checkout -n checkout --replicas 10
# 현재는 1.25.16 2대 사용 중 확인
# Karpenter will scale looking at the aggregate resource requirements of unscheduled pods. We will see we have now two nodes provisioned via karpenter.
kubectl get nodes -l team=checkout
NAME STATUS ROLES AGE VERSION
ip-10-0-24-213.us-west-2.compute.internal Ready <none> 62s v1.25.16-eks-59bf375
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 24h v1.25.16-eks-59bf375
# Lets get the ami id for the AMI build for kubernetes version 1.26.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text
ami-086414611b43bb691
[파일 수정]
We are making following changes in the default-**ec2nc**.yaml and default-**np**.yaml in eks-gitops-repo/app/karpenter folder as shown below.
우리는 spec.**amiSelectorTerms**의 AMI ID를 default-**ec2nc**.yaml파일의 위 출력으로 대체할 것입니다
We will add below code snippet under spec.disruption to add disruption budgets to disrupt all nodes at once.
budgets:
- nodes: "1"
Changes in default-ec2nc.yaml file
kubectl get ec2nodeclass default -o yaml | grep 'id: ami-' | uniq
- id: ami-0ee947a6f4880da75
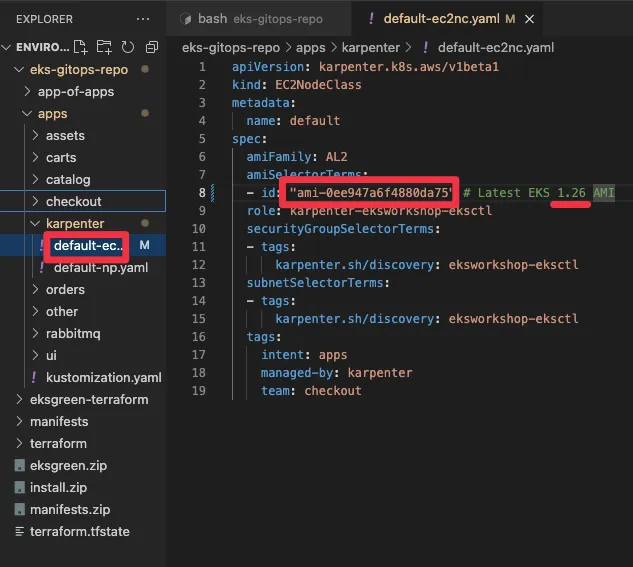
Changes in default-np.yaml file
kubectl get nodepool default -o yaml
...
spec:
disruption:
budgets:
- nodes: "1"
consolidationPolicy: WhenUnderutilized
expireAfter: Never
limits:
...

☞ To apply these changes we will commit and push these changes to the repository.

#
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
# 10분 소요 (예상) 실습 포함
cd ~/environment/eks-gitops-repo
git add apps/karpenter/default-ec2nc.yaml apps/karpenter/default-np.yaml
git commit -m "disruption changes"
git push --set-upstream origin main
argocd app sync karpenter
# Once Argo CD sync the karpenter app, we can see the disruption event in karpenter controller logs. It will then provision new nodes with kubernetes version 1.26 and delete the old nodes.
kubectl -n karpenter logs deployment/karpenter -c controller --tail=33 -f
혹은
kubectl stern -n karpenter deployment/karpenter -c controller
# Lets get the ami id for the AMI build for kubernetes version 1.26.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text
ami-086414611b43bb691
카펜터 컨트롤러 로그에서 노드 ip-10-0-11-205.us -west-2.compute.internal과 ip-10-0-47-152.us -west-2.compute.internal이 하나씩 표류하는 것을 볼 수 있습니다.
새 노드를 가져와서 이 노드에서 체크아웃 앱 포드가 실행되고 있는지 확인해 보겠습니다. 이제 노드가 v1.26.15-eks-1552ad0 버전에 있는지 확인할 수 있습니다.
# 과정 중 상태
Wed Mar 26 03:52:39 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-m4bv4 m6a.large us-west-2b ip-10-0-24-213.us-west-2.compute.internal True 15m
default-rpl9w c5.xlarge us-west-2c ip-10-0-39-95.us-west-2.compute.internal True 25h
default-xxf6m c5.xlarge us-west-2c ip-10-0-36-63.us-west-2.compute.internal True 45s
ip-10-0-24-213.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-36-63.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-39-95.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"},
>> {"effect":"NoSchedule","key":"karpenter.sh/disruption","value":"disrupting"}]
NAME STATUS ROLES AGE VERSION
ip-10-0-24-213.us-west-2.compute.internal Ready <none> 14m v1.25.16-eks-59bf375
ip-10-0-36-63.us-west-2.compute.internal Ready <none> 22s v1.26.15-eks-59bf375
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 25h v1.25.16-eks-59bf375
#
Wed Mar 26 03:54:15 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-rngwl m6a.large us-west-2b ip-10-0-21-135.us-west-2.compute.internal True 79s
default-xxf6m c5.xlarge us-west-2c ip-10-0-36-63.us-west-2.compute.internal True 2m22s
ip-10-0-21-135.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-36-63.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME STATUS ROLES AGE VERSION
ip-10-0-21-135.us-west-2.compute.internal Ready <none> 55s v1.26.15-eks-59bf375
ip-10-0-36-63.us-west-2.compute.internal Ready <none> 119s v1.26.15-eks-59bf375
# 카펜터 동작 로그 확인
kubectl -n karpenter logs deployment/karpenter -c controller --tail=33 -f
혹은
kubectl stern -n karpenter deployment/karpenter -c controller
#
kubectl get nodes -l team=checkout
# 파드 신규 노드로 이전 완료
kubectl get pods -n checkout -o wide
...
※ checkout-redis PVC 가 이미 다른 곳에 연결되었있다고 하고 신규 파드가 연결되지 않을 경우 : AWS EBS에서 해당 볼륨 Force detach 로 해결
Step3-3. Data-Plane Upgrade [ Self managed Node-group ]
Step1. 기본 정보 확인
# Lets explore the self-managed nodes.
kubectl get nodes --show-labels | grep self-managed
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 30h v1.25.16-eks-59bf375 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m5.large,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=us-west-2,failure-domain.beta.kubernetes.io/zone=us-west-2b,k8s.io/cloud-provider-aws=a94967527effcefb5f5829f529c0a1b9,kubernetes.io/arch=amd64,kubernetes.io/hostname=ip-10-0-26-119.us-west-2.compute.internal,kubernetes.io/os=linux,node.kubernetes.io/instance-type=m5.large,node.kubernetes.io/lifecycle=self-managed,team=carts,topology.ebs.csi.aws.com/zone=us-west-2b,topology.kubernetes.io/region=us-west-2,topology.kubernetes.io/zone=us-west-2b
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 30h v1.25.16-eks-59bf375 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m5.large,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=us-west-2,failure-domain.beta.kubernetes.io/zone=us-west-2a,k8s.io/cloud-provider-aws=a94967527effcefb5f5829f529c0a1b9,kubernetes.io/arch=amd64,kubernetes.io/hostname=ip-10-0-6-184.us-west-2.compute.internal,kubernetes.io/os=linux,node.kubernetes.io/instance-type=m5.large,node.kubernetes.io/lifecycle=self-managed,team=carts,topology.ebs.csi.aws.com/zone=us-west-2a,topology.kubernetes.io/region=us-west-2,topology.kubernetes.io/zone=us-west-2a
# Verify if the pods are scheduled on self-managed nodes.
kubectl get pods -n carts -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
carts-7ddbc698d8-zts9k 1/1 Running 0 30h 10.0.31.72 ip-10-0-26-119.us-west-2.compute.internal <none> <none>
carts-dynamodb-6594f86bb9-8pzk5 1/1 Running 0 30h 10.0.30.122 ip-10-0-26-119.us-west-2.compute.internal <none> <none>
# lets perform in-place upgrade on the self-managed nodes.
자가 관리 노드를 업그레이드하려면 실행 템플릿에서 AMI를 업데이트해야 합니다.
이 워크숍에서는 테라폼을 사용하여 자가 관리 노드를 생성했습니다.
이를 통해 /home/ec2-user/Environment/terraform/base.tf 파일에서 AMI를 업데이트하고 변경 사항을 적용할 수 있습니다.
하지만 먼저 Kubernetes 버전 1.26에 해당하는 최신 AMI를 확인해 보겠습니다.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id --region $AWS_REGION --query "Parameter.Value" --output text
ami-086414611b43bb691
Step2. Update /home/ec2-user/environment/terraform/base.tf file with the AMI obtained from the previous command.
self_managed_node_groups = {
self-managed-group = {
instance_type = "m5.large"
.
.
.
# Additional configurations
ami_id = "ami-086414611b43bb691" # Replaced the latest AMI ID for EKS 1.26
subnet_ids = module.vpc.private_subnets
.
.
.
launch_template_use_name_prefix = true
}
}
Step3. Apply terraform changes.
#
while true; do kubectl get nodes -l node.kubernetes.io/lifecycle=self-managed; echo ; aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Name,Values=default-selfmng" --output table; echo ; date; sleep 1; echo; done
#
cd ~/environment/terraform/
terraform plan && terraform apply -auto-approve
Step4. Once it is completed. Now validate the nodes with the below command to make sure the version is v1.26:
신규 버전 EC2 1대가 Ready되고 나서 5분 Refresh 시간 이후에 기존 버전 EC2 1대를 종료 실행하면서, 동시에 추가 신규 버전 EC2 1대 생성.

#
kubectl get nodes -l node.kubernetes.io/lifecycle=self-managed
NAME STATUS ROLES AGE VERSION
ip-10-0-19-69.us-west-2.compute.internal Ready <none> 23m v1.26.15-eks-1552ad0
ip-10-0-46-19.us-west-2.compute.internal Ready <none> 28m v1.26.15-eks-1552ad0
#
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Name,Values=default-selfmng" --output table
...

Step3-4. Data-Plane Upgrade [ Fargate Node-group ]
Fargate는 컨테이너에 필요에 따라 적절한 크기의 컴퓨팅 용량을 제공하는 기술입니다.
Fargate를 사용하면 컨테이너를 실행하기 위해 가상 머신 그룹을 직접 프로비저닝, 구성 또는 확장할 필요가 없습니다.
서버 유형을 선택하거나 노드 그룹을 확장할 시기를 결정하거나 클러스터 패킹을 최적화할 필요도 없습니다.
Fargate에서 실행되는 기준을 충족하는 Pod를 시작하면 클러스터에서 실행 중인 Fargate 컨트롤러가 Pod를 Fargate로 인식, 업데이트 및 예약합니다.
AWS Fargate 노드를 업그레이드하려면 K8s 배포를 다시 시작하여 새로운 포드가 최신 Kubernetes 버전에서 자동으로 예약되도록 할 수 있습니다.
Step1. 기본 정보 확인
#
kubectl get pods -n assets -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
assets-7ccc84cb4d-s8wwb 1/1 Running 0 31h 10.0.41.147 fargate-ip-10-0-41-147.us-west-2.compute.internal <none> <none>
# Now, lets describe the node to see its version.
kubectl get node $(kubectl get pods -n assets -o jsonpath='{.items[0].spec.nodeName}') -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 31h v1.25.16-eks-2d5f260 10.0.41.147 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
Step2. 디플로이먼트 재시작 Restart 으로 신규 버전 마이그레이션!
# 디플로이먼트 재시작 Restart
kubectl rollout restart deployment assets -n assets
# Lets wait for the new pods to become ready.
kubectl wait --for=condition=Ready pods --all -n assets --timeout=180s
# Once the new pods reach ready state, check the version of the new fargate node.
kubectl get pods -n assets -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
assets-569dcdcf9-xwscf 1/1 Running 0 72s 10.0.21.44 fargate-ip-10-0-21-44.us-west-2.compute.internal <none> <none>
kubectl get node $(kubectl get pods -n assets -o jsonpath='{.items[0].spec.nodeName}') -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
fargate-ip-10-0-21-44.us-west-2.compute.internal Ready <none> 38s v1.26.15-eks-2d5f260 10.0.21.44 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25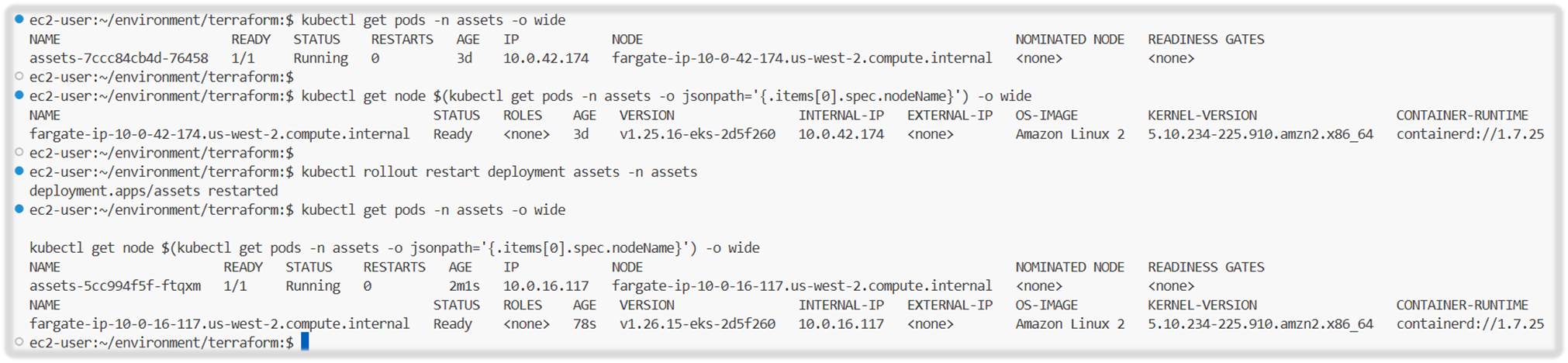
Step3. Data-Plane Upgrade [ 제어부와 동일한 데이터 노드 업그레이드 최종 확인 ]
#
kubectl get node
NAME STATUS ROLES AGE VERSION
fargate-ip-10-0-20-30.us-west-2.compute.internal Ready <none> 12m v1.26.15-eks-2d5f260
ip-10-0-19-132.us-west-2.compute.internal Ready <none> 11h v1.26.15-eks-59bf375
ip-10-0-3-241.us-west-2.compute.internal Ready <none> 14m v1.26.15-eks-59bf375
ip-10-0-33-62.us-west-2.compute.internal Ready <none> 3m21s v1.26.15-eks-1552ad0
ip-10-0-33-7.us-west-2.compute.internal Ready <none> 11h v1.26.15-eks-59bf375
ip-10-0-43-67.us-west-2.compute.internal Ready <none> 8m49s v1.26.15-eks-59bf375
ip-10-0-5-91.us-west-2.compute.internal Ready <none> 2m1s v1.26.15-eks-1552ad0
ip-10-0-6-214.us-west-2.compute.internal Ready <none> 36m v1.26.15-eks-59bf375
ip-10-0-7-148.us-west-2.compute.internal Ready <none> 10h v1.26.15-eks-59bf375
#
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --output table
#
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool
kubectl get node --label-columns=node.kubernetes.io/instance-type,kubernetes.io/arch,kubernetes.io/os,topology.kubernetes.io/zone
◇ (옵션) ArgoCD 에서 apps 삭제 후 다시 생성
1. ArgoCD 에서 apps 삭제

2. ArgoCD 에 apps 다시 생성
#
kubectl ctx blue
# Login to ArgoCD Console using credentials from following commands:
export ARGOCD_SERVER=$(kubectl get svc argo-cd-argocd-server -n argocd -o json | jq --raw-output '.status.loadBalancer.ingress[0].hostname')
argo_creds=$(aws secretsmanager get-secret-value --secret-id argocd-user-creds --query SecretString --output text)
# apps 다시 생성
argocd app create apps --repo $(echo $argo_creds | jq -r .url) --path app-of-apps \
--dest-server https://kubernetes.default.svc --sync-policy automated --revision main --server ${ARGOCD_SERVER}
# 생성 확인
argocd repo list
argocd app list
argocd app get apps
#
kubectl get pod -A
4-2. Blue-Green Cluster Upgrades
[ 소개 ]
1. 사전 준비
- Review release notes from both Kubernetes and EKS.
- Review the compatibility for your add-ons. . Upgrade your Kubernetes add-ons and custom controllers.
- Identify and remediate the use of deprecated and removed APIs in your workloads.
- Back up the cluster (if desired).
2. 가장 간단한 형태로, Blue-Green EKS 클러스터 업그레이드는 다음 단계들로 구성됩니다:
- 최신 또는 원하는 K8 버전의 새 EKS 클러스터 출시
- 필요에 따라 호환되는 Kubernetes 애드온 및 사용자 지정 컨트롤러 배포
- 워크로드를 새 클러스터에 배포합니다(필요에 따라 API 사용 중단에 업데이트 적용)
- 파란색 클러스터에서 녹색 클러스터로 트래픽 라우팅
필요에 따라 사용되지 않는 API와 업데이트된 Kubernetes 매니페스트를 제거하여 적절한 리소스를 업데이트하면 됩니다. 위의 순서대로 클러스터를 업그레이드할 수 있습니다. 이러한 단계는 테스트 환경에서 완료까지 가장 잘 수행되므로 클러스터 구성의 문제를 발견하고 애플리케이션이 프로덕션 클러스터에서 업그레이드 작업 전에 나타날 수 있습니다.
▶ 테라폼 코드 : Green EKS
ec2-user:~/environment:$ export EFS_ID=$(aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text)
ec2-user:~/environment:$ echo $EFS_ID
fs-0f1c146a65c620381
ec2-user:~/environment:$ ls -lrt eksgreen-terraform/
total 24
-rw-r--r--. 1 ec2-user ec2-user 542 Sep 1 2024 versions.tf
-rw-r--r--. 1 ec2-user ec2-user 15 Sep 1 2024 README.md
-rw-r--r--. 1 ec2-user ec2-user 464 Sep 8 2024 variables.tf
-rw-r--r--. 1 ec2-user ec2-user 4849 Sep 8 2024 addons.tf
-rw-r--r--. 1 ec2-user ec2-user 4010 Sep 8 2024 base.tf1. versions.tf
terraform {
required_version = ">= 1.3"
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 5.34"
}
helm = {
source = "hashicorp/helm"
version = ">= 2.9"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.20"
}
}
# ## Used for end-to-end testing on project; update to suit your needs
# backend "s3" {
# bucket = "terraform-ssp-github-actions-state"
# region = "us-west-2"
# key = "e2e/karpenter/terraform.tfstate"
# }
}
2. variables.tf
variable "cluster_version" {
description = "EKS cluster version."
type = string
default = "1.30"
}
variable "mng_cluster_version" {
description = "EKS cluster mng version."
type = string
default = "1.30"
}
variable "ami_id" {
description = "EKS AMI ID for node groups"
type = string
default = ""
}
variable "efs_id" {
description = "The ID of the already provisioned EFS Filesystem"
type = string
}3. base.tf
provider "aws" {
region = local.region
}
# Required for public ECR where Karpenter artifacts are hosted
provider "aws" {
region = "us-east-1"
alias = "virginia"
}
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
provider "helm" {
kubernetes {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
}
data "aws_partition" "current" {}
data "aws_caller_identity" "current" {}
data "aws_ecrpublic_authorization_token" "token" {
provider = aws.virginia
}
# Data source to reference the existing VPC
data "aws_vpc" "existing_vpc" {
filter {
name = "tag:Name"
values = [local.name]
}
}
data "aws_subnets" "existing_private_subnets" {
filter {
name = "vpc-id"
values = [ data.aws_vpc.existing_vpc.id ]
}
filter {
name = "tag:karpenter.sh/discovery"
values = [local.name]
}
}
data "aws_availability_zones" "available" {}
# tflint-ignore: terraform_unused_declarations
variable "eks_cluster_id" {
description = "EKS cluster name"
type = string
}
variable "aws_region" {
description = "AWS Region"
type = string
}
locals {
name = var.eks_cluster_id
region = var.aws_region
#vpc_cidr = "10.0.0.0/16"
#azs = slice(data.aws_availability_zones.available.names, 0, 3)
tags = {
Blueprint = "${local.name}-gr"
GithubRepo = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
}
################################################################################
# Cluster
################################################################################
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.14"
cluster_name = "${local.name}-gr"
cluster_version = "1.30"
cluster_endpoint_public_access = true
vpc_id = data.aws_vpc.existing_vpc.id
subnet_ids = data.aws_subnets.existing_private_subnets.ids
enable_cluster_creator_admin_permissions = true
eks_managed_node_group_defaults = {
cluster_version = var.mng_cluster_version
}
eks_managed_node_groups = {
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
}
}
# For demonstrating node-termination-handler
self_managed_node_groups = {
default-selfmng = {
instance_type = "m5.large"
min_size = 2
max_size = 4
desired_size = 2
# Additional configurations
subnet_ids = data.aws_subnets.existing_private_subnets.ids
disk_size = 100
# Optional
bootstrap_extra_args = "--kubelet-extra-args '--node-labels=node.kubernetes.io/lifecycle=self-managed,team=carts,type=OrdersMNG'"
# Required for self-managed node groups
create_launch_template = true
launch_template_use_name_prefix = true
}
}
tags = merge(local.tags, {
# NOTE - if creating multiple security groups with this module, only tag the
# security group that Karpenter should utilize with the following tag
# (i.e. - at most, only one security group should have this tag in your account)
"karpenter.sh/discovery" = "${local.name}-gr"
})
}
resource "time_sleep" "wait_60_seconds" {
create_duration = "60s"
depends_on = [module.eks]
}4. addons.tf
################################################################################
# EKS Blueprints Addons
################################################################################
module "eks_blueprints_addons" {
depends_on = [ time_sleep.wait_60_seconds ]
source = "aws-ia/eks-blueprints-addons/aws"
version = "~> 1.16"
cluster_name = module.eks.cluster_name
cluster_endpoint = module.eks.cluster_endpoint
cluster_version = module.eks.cluster_version
oidc_provider_arn = module.eks.oidc_provider_arn
# We want to wait for the Fargate profiles to be deployed first
create_delay_dependencies = [for prof in module.eks.fargate_profiles : prof.fargate_profile_arn]
eks_addons = {
coredns = {
addon_version = "v1.11.3-eksbuild.1"
}
vpc-cni = {
most_recent = true
}
kube-proxy = {
addon_version = "v1.30.3-eksbuild.2"
}
aws-ebs-csi-driver = {
service_account_role_arn = module.ebs_csi_driver_irsa.iam_role_arn
}
}
enable_karpenter = true
enable_aws_efs_csi_driver = true
enable_argocd = true
enable_aws_load_balancer_controller = true
enable_metrics_server = true
argocd = {
set = [
{
name = "server.service.type"
value = "LoadBalancer"
}
]
wait = true
}
aws_load_balancer_controller = {
set = [
{
name = "vpcId"
value = data.aws_vpc.existing_vpc.id
},
{
name = "region"
value = local.region
},
{
name = "podDisruptionBudget.maxUnavailable"
value = 1
},
{
name = "enableServiceMutatorWebhook"
value = "false"
}
]
wait = true
}
karpenter_node = {
# Use static name so that it matches what is defined in `karpenter.yaml` example manifest
iam_role_use_name_prefix = false
}
tags = local.tags
}
resource "time_sleep" "wait_90_seconds" {
create_duration = "90s"
depends_on = [module.eks_blueprints_addons]
}
resource "aws_eks_access_entry" "karpenter_node_access_entry" {
cluster_name = module.eks.cluster_name
principal_arn = module.eks_blueprints_addons.karpenter.node_iam_role_arn
# kubernetes_groups = []
type = "EC2_LINUX"
lifecycle {
ignore_changes = [
user_name
]
}
}
################################################################################
# Supporting Resources
################################################################################
module "ebs_csi_driver_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "~> 5.20"
role_name_prefix = "${module.eks.cluster_name}-ebs-csi-driver-"
attach_ebs_csi_policy = true
oidc_providers = {
main = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["kube-system:ebs-csi-controller-sa"]
}
}
tags = local.tags
}
################################################################################
# Storage Classes
################################################################################
resource "kubernetes_annotations" "gp2" {
api_version = "storage.k8s.io/v1"
kind = "StorageClass"
# This is true because the resources was already created by the ebs-csi-driver addon
force = "true"
metadata {
name = "gp2"
}
annotations = {
# Modify annotations to remove gp2 as default storage class still retain the class
"storageclass.kubernetes.io/is-default-class" = "false"
}
depends_on = [
module.eks_blueprints_addons
]
}
resource "kubernetes_storage_class_v1" "gp3" {
metadata {
name = "gp3"
annotations = {
# Annotation to set gp3 as default storage class
"storageclass.kubernetes.io/is-default-class" = "true"
}
}
storage_provisioner = "ebs.csi.aws.com"
allow_volume_expansion = true
reclaim_policy = "Delete"
volume_binding_mode = "WaitForFirstConsumer"
parameters = {
encrypted = true
fsType = "ext4"
type = "gp3"
}
depends_on = [
module.eks_blueprints_addons
]
}
# done: update parameters
resource "kubernetes_storage_class_v1" "efs" {
metadata {
name = "efs"
}
storage_provisioner = "efs.csi.aws.com"
reclaim_policy = "Delete"
parameters = {
provisioningMode = "efs-ap"
fileSystemId = var.efs_id
directoryPerms = "755"
gidRangeStart = "1000" # optional
gidRangeEnd = "2000" # optional
basePath = "/dynamic_provisioning" # optional
subPathPattern = "$${.PVC.namespace}/$${.PVC.name}" # optional
ensureUniqueDirectory = "false" # optional
reuseAccessPoint = "false" # optional
}
mount_options = [
"iam"
]
depends_on = [
module.eks_blueprints_addons
]
}▶ 신규 Green EKS 클러스터 생성 : 20분 소요 (예상) 실습 포함
이 실험실 섹션에서는 v1.30과 원하는 구성의 새로운 EKS 클러스터를 생성합니다. 이는 블루그린 클러스터 업그레이드 전략을 사용하면 한 번에 여러 K8S 버전을 뛰어넘거나 하나씩 여러 업그레이드를 수행할 수 있기 때문입니다. EKS 클러스터는 이전 클러스터와 동일한 VPC 내에서 생성됩니다. 이를 통해 여러 가지 이점을 얻을 수 있습니다:
- 네트워크 연결성: 두 클러스터를 동일한 VPC에 유지하면 리소스 간의 원활한 통신이 보장되어 워크로드와 데이터를 더 쉽게 마이그레이션할 수 있습니다.
- 공유 자원: NAT 게이트웨이, VPN 연결, Direct Connect와 같은 기존 VPC 자원을 재사용할 수 있어 복잡성과 비용을 줄일 수 있습니다.
- 보안 그룹: 두 클러스터 모두에서 일관된 보안 그룹 규칙을 유지하여 보안 관리를 간소화할 수 있습니다.
- 서비스 검색: AWS 클라우드 맵 또는 유사한 서비스 검색 메커니즘을 사용하면 서비스가 클러스터 간에 서로를 더 쉽게 찾을 수 있습니다.
- 서브넷 활용: 기존 서브넷을 효율적으로 활용할 수 있어 새로운 네트워크 범위를 프로비저닝할 필요가 없습니다.
- VPC 피어링: VPC가 다른 VPC와 피어링되는 경우, 이러한 연결은 두 클러스터 모두에서 유효하게 유지됩니다.
- 일관된 DNS: 동일한 VPC를 사용하면 프라이빗 DNS 존과 Route 53 구성을 일관되게 사용할 수 있습니다.
- IAM 및 리소스 정책: 많은 IAM 역할과 리소스 정책이 VPC에 적용되므로 동일한 VPC를 사용하면 권한 관리가 간소화됩니다.
Step1. 이전에 생성된 EFS 파일 시스템의 ID를 검색
이전에 인플레이스 업그레이드를 위해 클러스터를 만들 때, 우리는 EFS 파일 시스템을 생성하는 약간의 추가 Terraform 코드를 삽입하여 Blue-Green 전략에 이를 활용할 수 있도록 했습니다. 더 나아가기 전에, 해당 EFS 파일 시스템의 ID를 기록해야 합니다. 이 값은 스토리지클래스 및 StatefulSet Resources를 생성할 때 사용할 것이기 때문입니다.
#
export EFS_ID=$(aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text)
echo $EFS_ID
Step2. 신규 Green EKS 클러스터 생성 : 20분 소요 (예상) 실습 포함
#
watch -d 'aws ec2 describe-instances --filters "Name=instance-state-name,Values=running" --query "Reservations[*].Instances[*].[InstanceId, InstanceType, PublicIpAddress]" --output table'
--------------------------------------------------------
| DescribeInstances |
+----------------------+------------+------------------+
| i-08420b68326484f45 | m5.large | None |
| i-066e3e3c4b57d1970 | c4.xlarge | None |
| i-075afcf031d4f8d9e | m5.large | None |
| i-0b4cdf8ef78b5ae0a | m5.large | None |
| i-0ce0395137307f416 | m5.large | None |
| i-078050b6ce3ebfb8f | m5.large | None |
| i-06f9c6c2d3d6f56ab | c5.large | None |
| i-00d9a1ac022bd4f29 | t3.medium | 34.219.198.103 |
| i-006c25139e1b2f1ef | m5.large | None |
+----------------------+------------+------------------+
#
cd ~/environment
unzip eksgreen.zip
tree eksgreen-terraform/
eksgreen-terraform/
├── README.md
├── addons.tf
├── base.tf
├── variables.tf
└── versions.tf
#
cd eksgreen-terraform
terraform init
terraform plan -var efs_id=$EFS_ID
terraform apply -var efs_id=$EFS_ID -auto-approve
Step3. Update Kubectl Context : 별칭 사용
# KUBECTL context 업데이트
aws eks --region ${AWS_REGION} update-kubeconfig --name ${EKS_CLUSTER_NAME} --alias blue && \
kubectl config use-context blue
aws eks --region ${AWS_REGION} update-kubeconfig --name ${EKS_CLUSTER_NAME}-gr --alias green && \
kubectl config use-context green
# 클러스터 설정 확인
cat ~/.kube/config
kubectl ctx
kubectl ctx green
# Verify the EC2 worker nodes are attached to the cluster
kubectl get nodes --context green
NAME STATUS ROLES AGE VERSION
ip-10-0-20-212.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-21-169.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-35-26.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-9-126.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
# Verify the operational Addons on the cluster:
helm list -A --kube-context green
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
argo-cd argocd 1 2025-03-26 11:58:02.453602353 +0000 UTC deployed argo-cd-5.55.0 v2.10.0
aws-efs-csi-driver kube-system 1 2025-03-26 11:58:30.395245866 +0000 UTC deployed aws-efs-csi-driver-2.5.6 1.7.6
aws-load-balancer-controller kube-system 1 2025-03-26 11:58:31.887699595 +0000 UTC deployed aws-load-balancer-controller-1.7.1 v2.7.1
karpenter karpenter 1 2025-03-26 11:58:31.926407743 +0000 UTC deployed karpenter-0.37.0 0.37.0
metrics-server kube-system 1 2025-03-26 11:58:02.447165223 +0000 UTC deployed metrics-server-3.12.0 0.7.0
Step4. [옵션] kube-ops-view 설치
#
kubectl ctx green
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm repo update
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --namespace kube-system
#
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-type: external
labels:
app.kubernetes.io/instance: kube-ops-view
app.kubernetes.io/name: kube-ops-view
name: kube-ops-view-nlb
namespace: kube-system
spec:
type: LoadBalancer
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/instance: kube-ops-view
app.kubernetes.io/name: kube-ops-view
EOF
# kube-ops-view 접속 URL 확인 (1.5, 1.3 배율)
kubectl get svc -n kube-system kube-ops-view-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "KUBE-OPS-VIEW URL = http://"$1"/#scale=1.5"}'
kubectl get svc -n kube-system kube-ops-view-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "KUBE-OPS-VIEW URL = http://"$1"/#scale=1.3"}'
▶ Stateless Workload Migration - ArgoCD , UI HPA 수정 → blue 는 직접 수정하자
1) Stateless application upgrade process
상태 비저장 애플리케이션은 클러스터에 영구 데이터를 보관할 필요가 없으므로 업그레이드 중에 새 녹색 클러스터에 배포하고 트래픽을 라우팅하기만 하면 됩니다.
이 워크숍에서는 이미 AWS CodeCommit eks-gitops-repo에 리테일 스토어 앱의 진실 소스를 생성하고 ArgoCD를 사용하여 Blue 클러스터에 배포했습니다. 이러한 진실 소스를 확보하는 것은 Blue-Green 클러스터 업그레이드를 수행하는 데 있어 매우 중요합니다. 따라서 eks-gitops-repo로 새 클러스터를 부트스트랩하여 애플리케이션을 배포하기만 하면 됩니다.
부트스트래핑 전에 최신 1.30 K8S 버전을 준수하도록 애플리케이션을 변경해야 합니다. 클러스터 업그레이드 준비 모듈에서 설명한 것처럼, EKS 업그레이드 인사이트, kubent와 같은 도구를 사용하여 사용되지 않는 API 사용량을 찾아 이를 완화할 수 있습니다.
2) GitOps Repo Setup : UI HPA 수정
a. 부트스트래핑 프로세스를 시작합니다:
- 그린 클러스터에 필요한 변경 사항을 분리하기 위해 새로운 git 브랜치를 사용하여 수정 사항을 유지하고 이 브랜치를 사용하여 그린 클러스터를 부트스트랩할 예정입니다.
#
cd ~/environment/eks-gitops-repo
git status
git branch
* main
# Create the new local branch green
git switch -c green
git branch -a
* green
main
remotes/origin/HEAD -> origin/main
remotes/origin/main
b. 이제 관련 K8s 매니페스트를 1.30개의 세부 정보로 업데이트하세요.
예를 들어, 1.26 Amazon Linux 2 AMI와 IAM 역할 및 보안 그룹의 블루 클러스터를 참조하는 Karpenter EC2NodeClass가 있습니다. 따라서 1.30 Amazon Linux 2023 AMI와 그린 클러스터의 보안 그룹 및 IAM 역할을 사용하도록 업데이트해 보겠습니다. 다음 명령으로 AL2023 AMI를 가져옵니다:
export AL2023_130_AMI=$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.30/amazon-linux-2023/x86_64/standard/recommended/image_id --region ${AWS_REGION} --query "Parameter.Value" --output text)
echo $AL2023_130_AMI
ami-08eb2eb81143e2902
c. default-ec2nc.yaml에서 AMI ID, 보안 그룹, IAM 역할 및 기타 세부 정보를 업데이트합니다.
cat << EOF > ~/environment/eks-gitops-repo/apps/karpenter/default-ec2nc.yaml
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2023
amiSelectorTerms:
- id: "${AL2023_130_AMI}" # Latest EKS 1.30 AMI
role: karpenter-eksworkshop-eksctl-gr
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl-gr
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl
tags:
intent: apps
managed-by: karpenter
team: checkout
EOF
d. 이제 1.30에 비해 사용되지 않는 API 사용량을 확인해 보세요.
GitOps 저장소에서 사용되지 않는 API 사용량을 찾을 수 있도록 Pluto 유틸리티를 미리 설치했습니다. https://github.com/FairwindsOps/pluto


# 위에서 미리 조치를 해서 안나오지만, 미조치했을 경우 아래 처럼 코드 파일 내용으로 검출 가능!
pluto detect-files -d ~/environment/eks-gitops-repo/
NAME KIND VERSION REPLACEMENT REMOVED DEPRECATED REPL AVAIL
ui HorizontalPodAutoscaler autoscaling/v2beta2 autoscaling/v2 false true false
# 매니페스트를 다른 API 버전 간 변환 ( kubectl convert )
kubectl convert -f apps/ui/hpa.yaml --output-version autoscaling/v2 -o yaml > apps/ui/tmp.yaml && mv apps/ui/tmp.yaml apps/ui/hpa.yaml
#
cat apps/ui/hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ui
namespace: ui
spec:
minReplicas: 1
maxReplicas: 4
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ui
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
e. 마지막으로, 녹색 브랜치를 사용할 ArgoCD 앱 애플리케이션을 가리킬 것입니다.
Lastly, we will point the ArgoCD apps application to use the green branch.
#
cat app-of-apps/values.yaml
spec:
destination:
# HIGHLIGHT
server: https://kubernetes.default.svc
source:
# HIGHLIGHT
repoURL: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
# HIGHLIGHT
targetRevision: main
# HIGHLIGHT
applications:
- name: assets
- name: carts
- name: catalog
- name: checkout
- name: orders
- name: other
- name: rabbitmq
- name: ui
- name: karpenter
#
sed -i 's/targetRevision: main/targetRevision: green/' app-of-apps/values.yaml
# Commit the change to green branch and push it to the CodeCommit repo.
git add . && git commit -m "1.30 changes"
git push -u origin green[ 수행 결과 ]
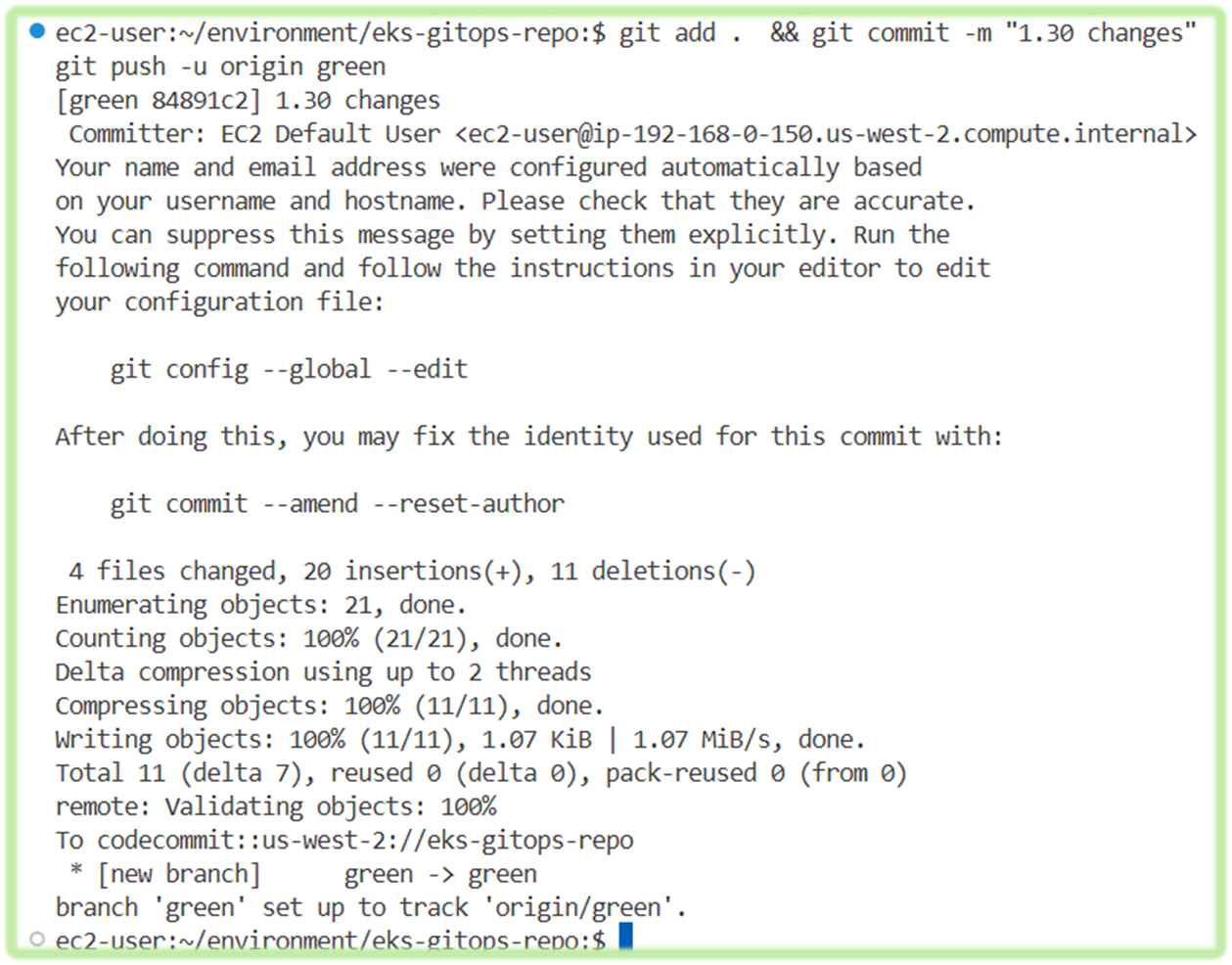
3) ArgoCD Setup on Green EKS Cluster - ArgoCD
# Login to ArgoCD using credentials from the following commands:
export ARGOCD_SERVER_GR=$(kubectl get svc argo-cd-argocd-server -n argocd -o json --context green | jq --raw-output '.status.loadBalancer.ingress[0].hostname')
echo "ArgoCD URL: http://${ARGOCD_SERVER_GR}"
export ARGOCD_USER_GR="admin"
export ARGOCD_PWD_GR=$(kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" --context green | base64 -d)
echo "Username: ${ARGOCD_USER_GR}"
echo "Password: ${ARGOCD_PWD_GR}"
# Alternatively you can login using ArgoCD CLI:
argocd login --name green ${ARGOCD_SERVER_GR} --username ${ARGOCD_USER_GR} --password ${ARGOCD_PWD_GR} --insecure --skip-test-tls --grpc-web
'admin:login' logged in successfully
Context 'green' updated

a. Register the AWS CodeCommit Git Repo in the ArgoCD:
#
argo_creds=$(aws secretsmanager get-secret-value --secret-id argocd-user-creds --query SecretString --output text)
argocd repo add $(echo $argo_creds | jq -r .url) --username $(echo $argo_creds | jq -r .username) --password $(echo $argo_creds | jq -r .password) --server ${ARGOCD_SERVER_GR}
Repository 'https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo' added

b. Deploy the retail-store-sample application components on the green cluster, we are using ArgoCD App of Apps patterns to deploy all components of the retail-store-sample
#
argocd app create apps --repo $(echo $argo_creds | jq -r .url) --path app-of-apps \
--dest-server https://kubernetes.default.svc --sync-policy automated --revision green --server ${ARGOCD_SERVER_GR}
#
argocd app list --server ${ARGOCD_SERVER_GR}
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/apps https://kubernetes.default.svc default Synced Healthy Auto <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo app-of-apps green
argocd/assets https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/assets green
argocd/carts https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/carts green
argocd/catalog https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/catalog green
argocd/checkout https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/checkout green
argocd/karpenter https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/karpenter green
argocd/orders https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/orders green
argocd/other https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/other green
argocd/rabbitmq https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/rabbitmq green
argocd/ui https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/ui green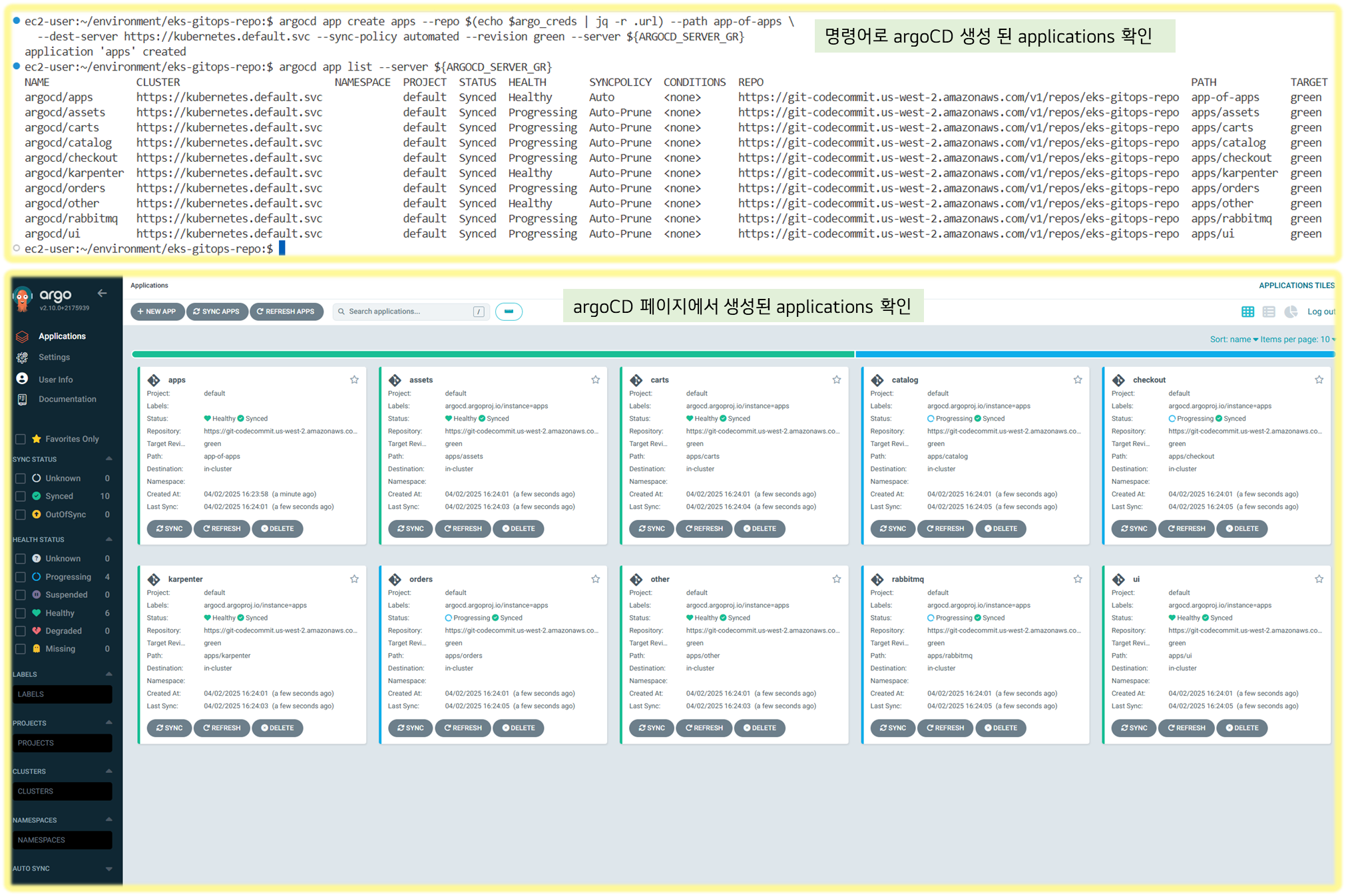
4) Traffic Routing
애플리케이션이 배포되면 다음으로 중요한 것은 트래픽을 파란색에서 녹색 클러스터로 전환하는 방법입니다.
Amazon Route 53의 가중치 기록, AWS 애플리케이션 로드 밸런서의 가중치 대상 그룹 등 다양한 기술을 사용할 수 있습니다.
Amazon Route 53 가중치 리소스 레코드를 사용하면 각 클러스터에 정의된 입력 리소스를 가리키는 DNS 레코드의 가중치를 변경하여 청록색 업그레이드 또는 카나리아 스타일 마이그레이션 중에 트래픽을 전환할 수 있습니다.
루트 53 가중치 레코드를 사용하면 도메인 이름(example.com )으로 향하는 트래픽을 여러 다른 엔드포인트로 가리킬 수 있습니다. 동일한 이름과 유형을 가진 여러 레코드에 0에서 255 사이의 가중치를 할당할 수 있습니다. 루트 53은 가중치 집합의 모든 레코드에 대한 가중치의 합을 계산하고, 가중치를 총 가중치의 비율로 기준으로 각 레코드로 트래픽을 라우팅합니다. 예를 들어, 가중치가 1과 3인 두 레코드가 있는 경우 첫 번째 레코드는 트래픽의 25%(1/4)를, 두 번째 레코드는 75%(3/4)를 받게 됩니다.
따라서 이 워크숍의 소매점 샘플 애플리케이션에서는 다음과 같이 작동합니다: * 파란색 클러스터 DNS 레코드 = 100이고 녹색 클러스터 DNS 레코드 = 0인 경우, Route 53은 모든 요청을 파란색 클러스터로 라우팅합니다. * 파란색 클러스터 DNS 레코드 = 0이고 녹색 클러스터 DNS 레코드 = 100인 경우, Route 53은 모든 요청을 녹색 클러스터로 라우팅합니다. * 파란색 클러스터 DNS 레코드 = 50, 녹색 클러스터 DNS 레코드 = 50과 같은 중간 값도 정의할 수 있어 파란색 클러스터와 녹색 클러스터 간의 요청 균형을 고르게 맞출 수 있습니다.
So, with our retail-store-sample application in this workshop, it will work like this: * If blue cluster DNS record = 100, and green cluster DNS record = 0, then Route 53 will route all requests to the blue cluster. * If blue cluster DNS record = 0, and green cluster DNS record = 100, then Route 53 will route all requests to the green cluster. * Intermediate values can also be define, such blue cluster DNS record = 50, and green cluster DNS record = 50, which will evenly balance requests between blue and green clusters.
external-dns addon to manage the Route 53 DNS records and weights. 이를 설정하고 사용하는 방법은 외부 DNS 문서를 참조하세요 - Link
You can leverage following annotations on an Ingress resource to setup the DNS record weights in Amazon Route 53.
입력 리소스에 대한 다음 주석을 활용하여 Amazon Route 53에서 DNS 레코드 가중치를 설정할 수 있습니다
external-dns.alpha.kubernetes.io/set-identifier: {{ .Values.spec.clusterName }}
external-dns.alpha.kubernetes.io/aws-weight: '{{ .Values.spec.ingress.route53_weight }}'
세트 식별자 주석에는 생성하려는 클러스터의 이름이 포함되며, 이는 외부-dns txTOwnerId 테라폼 구성에 정의된 것과 일치해야 합니다
The set-identifier annotation will contain the name of the cluster we want to create, which must match the one defined in the external-dns txtOwnerId terraform configuration
AWS 가중치 주석은 가중 레코드의 값을 구성하는 데 사용되며, 플랫폼 팀이 EKS 클러스터 간의 워크로드 마이그레이션 방법과 시기를 자율적으로 제어할 수 있도록 테라폼에서 주입하는 헬름 값에서 배포됩니다.
The aws-weight annotation will be used to configure the value of the weighted record, and it will be deployed from Helm values, that will be injected by Terraform so that a platform team will be able to control autonomously how and when they want to migrate workloads between the EKS clusters.
테라폼에서 관련 값을 업데이트하고 구성을 적용하여 워크로드 마이그레이션을 트리거할 수 있습니다.
You can trigger a workload migration by updating the relevant values in Terraform and applying the config.
▶ Stateful Workload Migration
☞ 이 워크숍의 목적은 그린 클러스터의 StatefulSet이 트래픽을 그린 클러스터로 리디렉션하고 청록색 업그레이드를 완료하는 HTML 파일에 액세스할 수 있다는 것입니다. 참고로, 일반적인 스테이트풀 애플리케이션에서는 환경의 특정 공유 스토리지 유형을 사용하여 클러스터 간에 이러한 파일을 동기화하고, 모든 업그레이드된 버전 애드온을 배포하며, 그린 클러스터로 트래픽을 전송하기 전에 애플리케이션이 작동하는지 확인합니다.
1) Stateful application upgrade process
이 실험실에서는 Blue-Green 업그레이드 전략에서 상태 기반 애플리케이션을 마이그레이션하는 방법을 시연할 것입니다.
필요한 경우 파란색 및 녹색 EKS 클러스터를 배포하려면 먼저 전제 조건을 수행해야 합니다. Amazon EFS 파일 시스템도 프로비저닝됩니다.
Make sure you perform the prerequisites first to deploy both the blue and green EKS clusters, if necessary. An Amazon EFS file system will also be provisioned.
Kubernetes에서 실행되는 상태 저장 애플리케이션을 위한 지속적인 스토리지 옵션은 Amazon EBS 볼륨이나 클러스터 간 동기화가 필요한 데이터베이스 컨테이너를 포함하여 다양합니다. 이 워크숍의 단순화를 위해 Amazon EFS 파일 시스템을 사용할 예정이지만, 일반적인 개념은 그대로 유지되어 파란색 녹색 프로세스를 사용하여 상태 저장 애플리케이션을 업그레이드할 수 있습니다.
There are numerous storage options to host persistent storage for a stateful application running in Kubernetes, including Amazon EBS volumes or potentially even a database container that would need to be synchronized between clusters. For simplicity of this workshop, we’ll be using an Amazon EFS file system, however the general concepts remain the same to upgrade a stateful application using the blue green process.
우리의 EFS 파일 시스템은 파란색과 초록색 클러스터 모두에 연결될 네트워크 파일 공유 볼륨을 제공할 것입니다.
Our EFS file system will provide a network file share volume that will be attached to both blue and green clusters.
상태 저장 애플리케이션이 있는 일반적인 청록색 클러스터 업그레이드에서는 트래픽을 청록색 클러스터에서 녹색 클러스터로 차단하기 전에 두 클러스터 간에 지속적인 스토리지가 동기화될 가능성이 높습니다. 이 워크숍에서는 클러스터 간 데이터를 동기화하는 대신, EFS 파일 시스템을 청록색 클러스터와 녹색 클러스터 모두에 간단히 마운트하여 동기화 과정을 시뮬레이션할 것입니다.
In a typical blue-green cluster upgrade with a stateful application, the persistent storage would likely be synchronized across both clusters before traffic can be cut over from blue to green clusters. For this workshop, instead of synchronizing data between the clusters, we will simulate the that synchronization process by simply mounting the EFS file system to both blue and green clusters.
지속적인 저장 공간을 갖춘 상태 저장 애플리케이션의 업그레이드를 시뮬레이션하려면 다음 단계를 따릅니다: * 파란색 클러스터에 Kubernetes StatefulSet 리소스 생성 * 파란색 클러스터에 수동으로 정적 HTML 파일을 생성하여 궁극적으로 공유 EFS 파일 시스템에 저장됩니다 * 녹색 클러스터에 nginx를 실행하는 포드를 호스팅하고 파란색 포드와 동일한 파일 저장소에 액세스하는 StatefulSet 리소스 생성 * (선택 사항) 파란색 클러스터에서 원래 StatefulSet 삭제
To simulate an upgrade of a stateful application with persistent storage, we will follow these steps in this order: * Create a Kubernetes StatefulSet resource on the Blue cluster * Manually create a static html file on the blue cluster, which will ultimately be stored on the shared EFS file system * Create a StatefulSet resource on the Green cluster that hosts pods running nginx, and will access the same file storage as the blue pods * (Optional) Delete the original StatefulSet from the Blue cluster
→ EFS File System ID 확인 : echo $EFS_ID ⇒ fs-067150b027d42f72b ( 자신의 ID 사용!!)
2) Create and deploy a StatefulSet in the blue cluster
StatefulSet은 지속적인 저장이 필요한 상태 저장 애플리케이션을 관리하는 데 사용됩니다. 이 워크숍의 목적을 위해, 포드 재조정 기간 동안 EFS 파일 공유에 지속적인 저장을 유지할 것입니다.
A StatefulSet is used to manage stateful applications that require persistent storage, among other benefits. For the purposes of this workshop, it will maintain persistent storage to our EFS file share across pod rescheduling.
이 StatefulSet은 1개의 nginx 포드를 배포합니다 This StatefulSet will deploy 1 nginx pod
이 StatefulSet은 Nginx 포드가 액세스할 수 있도록 EFS 파일 공유를 마운트합니다. 이후 단계에서는 동일한 EFS 파일 공유를 녹색 클러스터의 StatefulSet에 마운트하여 두 클러스터가 동일한 공유 파일에 액세스할 수 있도록 할 것입니다. 이를 통해 애플리케이션의 지속적인 스토리지 계층을 시뮬레이션할 수 있습니다.
Note that this StatefulSet mounts our EFS file share so the nginx Pods can access it. In a later step, we’ll also mount the same EFS file share to a StatefulSet in the green cluster, allowing both clusters to access the same shared files. This simulates a persistent storage layer for our application.
StorageClass 객체를 사용하면 EFS 파일 시스템에 필요한 매개변수를 지정할 수 있습니다. StatefulSet의 포드는 이 스토리지Class를 참조하여 파일 시스템을 마운트합니다.
A StorageClass object will allows us to specify the required parameters for the EFS file system. The pods in our StatefulSet refer to this StorageClass to mount the file system.
a. 우리는 EKS 블루 클러스터 내에서 작동하도록 쿠벡틀 컨텍스트를 설정할 것입니다. 이 명령을 실행하여 블루 클러스터에 연결합니다
#
kubectl ctx
arn:aws:eks:us-west-2:271345173787:cluster/eksworkshop-eksctl
blue
green
# We will set our kubectl context to work within the EKS blue cluster. Run this command to connect to the Blue cluster:
kubectl config use-context blue
Switched to context "blue".
# Run this command to review the StorageClass manifest (optional):
# eFS 파일 시스템의 ID를 참조하는 fileSystemId 필드에 주목하세요. 이 필드는 이전에 설정된 EFS_ID 값과 일치해야 합니다.
kubectl get storageclass efs -o yaml
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
creationTimestamp: "2025-03-30T05:50:08Z"
name: efs
resourceVersion: "3649"
uid: 159ccc38-1e11-451b-9064-2e79e30e9055
mountOptions:
- iam
parameters:
basePath: /dynamic_provisioning
directoryPerms: "755"
ensureUniqueDirectory: "false"
fileSystemId: fs-0f1c146a65c620381
gidRangeEnd: "200"
gidRangeStart: "100"
provisioningMode: efs-ap
reuseAccessPoint: "false"
subPathPattern: ${.PVC.namespace}/${.PVC.name}
provisioner: efs.csi.aws.com
reclaimPolicy: Delete
volumeBindingMode: Immediateb. Now deploy a StatefulSet manifest that uses the StorageClass:
cat <<EOF | kubectl apply -f -
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: efs-example
namespace: default
spec:
serviceName: "efs-example"
replicas: 1
selector:
matchLabels:
app: efs-example
template:
metadata:
labels:
app: efs-example
spec:
containers:
- name: app
image: nginx:latest
volumeMounts:
- name: efs-storage
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: efs-storage
spec:
accessModes: ["ReadWriteMany"]
storageClassName: efs
resources:
requests:
storage: 1Gi
EOF
c. 확인
#
kubectl get sts,pvc
NAME READY AGE
statefulset.apps/efs-example 1/1 29s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/efs-storage-efs-example-0 Bound pvc-bca0344c-55b8-43e9-9b30-821fb2fc8886 1Gi RWX efs 28s
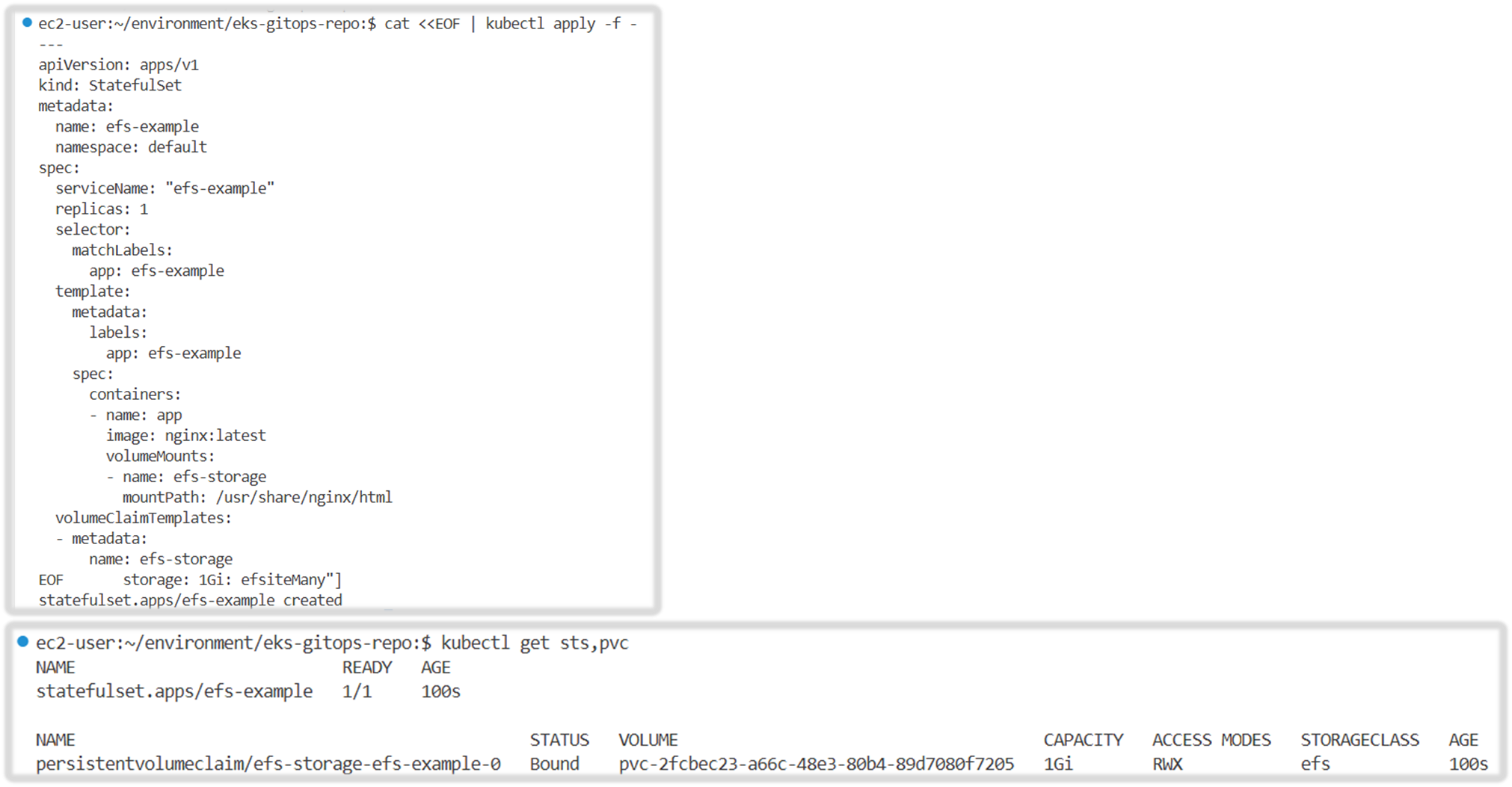
3) Create a static web page on the Blue cluster
우리는 간단한 정적 HTML 웹 페이지를 사용하여 영구 저장 장치가 있는 애플리케이션을 시뮬레이션할 것입니다. 일반적인 시나리오에서는 이 영구 계층 자산이 전체 데이터베이스일 수도 있고, 애플리케이션이 의존하는 다른 영구 파일일 수도 있습니다. 하지만 이 워크숍에서는 단일 정적 HTML 파일을 사용하여 영구 저장 자산을 표현할 것입니다. 다시 말해, 이 HTML 파일이 위치할 영구 저장 계층은 EFS 파일 공유로, 파란색 클러스터와 초록색 클러스터 모두에서 접근할 수 있습니다.
We will use a simple static html web page to simulate an application with persistent storage. In a typical scenario, this persistent layer assets could be an entire database, or other permanent files that the application depends on. But for the purposes of this workshop, we will just use a single static html file to represent persist storage assets. As a reminder, the persistent storage layer where this html file will reside is an EFS file share, accessed by both the blue and green clusters.
▶ Blue Cluster에 정적 웹 페이지 만들기
# Use the command below to create a new file named index.html in the directory /usr/share/nginx/html of one of the pods in the blue cluster:
# 아래 명령을 사용하여 파란색 클러스터에 있는 포드 중 하나의 디렉토리 /usr/share/nginx/html에 index.html이라는 새 파일을 만듭니다
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'touch /usr/share/nginx/html/index.html'
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'echo aews study 9w end! > /usr/share/nginx/html/index.html'
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'cat /usr/share/nginx/html/index.html'
# To confirm if our EFS file share works, check if this new file can be accessed by another pod in the same StatefulSet by running this command:
# EFS 파일 공유가 작동하는지 확인하려면 다음 명령을 실행하여 동일한 StatefulSet에 있는 다른 포드에서 이 새 파일에 액세스할 수 있는지 확인합니다:
kubectl delete pods -l app=efs-example && \
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'ls -lh /usr/share/nginx/html/index.html'
pod "efs-example-0" deleted
-rw-r--r-- 1 100 users 0 Mar 26 13:26 /usr/share/nginx/html/index.html
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'cat /usr/share/nginx/html/index.html'

4) Create a StatefulSet on the Green Cluster
a. Our first step is to change the context to the green cluster created earlier:
kubectl config use-context green
혹은
kubectl ctx green
b. Create StatefulSet with sharing of EFS
이제 녹색 클러스터에서 파란색 클러스터에서와 동일한 작업을 수행하여 녹색 클러스터의 애플리케이션이 EFS 파일 공유에 액세스할 수 있도록 StatefulSet을 만들겠습니다.
이 명령을 실행하여 매니페스트를 배포합니다:
cat <<EOF | kubectl apply -f -
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: efs-example
namespace: default
spec:
serviceName: "efs-example"
replicas: 1
selector:
matchLabels:
app: efs-example
template:
metadata:
labels:
app: efs-example
spec:
containers:
- name: app
image: nginx:latest
volumeMounts:
- name: efs-storage
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: efs-storage
spec:
accessModes: ["ReadWriteMany"]
storageClassName: efs
resources:
requests:
storage: 1Gi
EOF☞ 이전과 마찬가지로, StatefulSet은 클러스터가 시작될 때 생성되었으며, 스토리지를 할당하고 Pod와 연결하는 역할을 담당합니다
이제 인덱스.html 파일은 파란색 클러스터와 녹색 클러스터 모두에서 StatefulSet Pods에 의해 액세스할 수 있게 됩니다. 일반적인 파란색-녹색 업그레이드 시나리오에서는 애플리케이션의 지속적인 스토리지 계층 자산을 파란색 클러스터와 녹색 클러스터 간에 동기화하는 것을 고려할 수 있습니다. 또한 일반적으로 애플리케이션이 녹색 클러스터에서 의도한 대로 작동하는지 테스트하고, 애플리케이션이 예상대로 실행되는지 확신한 후에야 트래픽을 녹색 클러스터로 리디렉션할 수 있습니다.
c.Check Whether StatefulSet is able to access file of EFS
EFS 파일 공유가 작동하는지 확인하려면 다음 명령을 실행하여 동일한 StatefulSet에 있는 다른 포드에서 이 새 파일에 액세스할 수 있는지 확인합니다:
#
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'ls -lh /usr/share/nginx/html/index.html'
-rw-r--r--. 1 100 users 0 Mar 26 13:26 /usr/share/nginx/html/index.html
kubectl exec $(kubectl get pods -o jsonpath='{.items[0].metadata.name}' -l app=efs-example) -- bash -c 'cat /usr/share/nginx/html/index.html'
출력에 나열된 index.html 파일이 표시되어야 하며, 이는 녹색 클러스터가 파란색 클러스터에서 동일한 파일을 볼 수 있음을 나타냅니다.
파란색 클러스터는 여전히 /usr/share/nginx/html 파일 시스템에서 파일 잠금(FLOCK)을 유지하므로 녹색 클러스터에서 파일을 만들려고 하면 명령에서 권한 거부 오류가 발생합니다

5) Delete the StatefulSet from the blue cluster
☞ 이 워크숍의 목적을 위해, 우리는 모든 애플리케이션 테스트를 완료했으며, 업그레이드 과정을 완료하기 위해 애플리케이션 트래픽을 그린 클러스터로 이동시키는 데 자신이 있다는 점을 고려할 것입니다.
이 명령을 실행하여 Blue 클러스터에 연결합니다:
kubectl delete statefulset efs-example --context blue
▶ [ 옵션 ] Green Cluster 삭제 : 20분 이상 소요 (예상) 실습 포함
kubectl ctx green
kubectl delete statefulset efs-example
# kube-ops-view
kubectl delete svc -n kube-system kube-ops-view-nlb
helm uninstall kube-ops-view --namespace kube-system
#
cd ~/environment/eks-gitops-repo
git checkout main
git branch
#
cat ~/environment/eks-gitops-repo/apps/karpenter/default-ec2nc.yaml
cat ~/environment/eks-gitops-repo/apps/ui/hpa.yaml
cat ~/environment/eks-gitops-repo/app-of-apps/values.yaml
#
watch -d kubectl get pod -A
#
watch -d 'aws ec2 describe-instances --filters "Name=instance-state-name,Values=running" --query "Reservations[*].Instances[*].[InstanceId, InstanceType, PublicIpAddress]" --output table'
--------------------------------------------------------
| DescribeInstances |
+----------------------+------------+------------------+
| i-08420b68326484f45 | m5.large | None |
| i-066e3e3c4b57d1970 | c4.xlarge | None |
| i-075afcf031d4f8d9e | m5.large | None |
| i-0b4cdf8ef78b5ae0a | m5.large | None |
| i-0ce0395137307f416 | m5.large | None |
| i-078050b6ce3ebfb8f | m5.large | None |
| i-06f9c6c2d3d6f56ab | c5.large | None |
| i-00d9a1ac022bd4f29 | t3.medium | 34.219.198.103 |
| i-006c25139e1b2f1ef | m5.large | None |
+----------------------+------------+------------------+
#
cd ~/environment/eksgreen-terraform
terraform destroy -var efs_id=$EFS_ID -auto-approve
☞ 마지막 남은 SG 1개가 잘 삭제가 안될 경우에는 AWS 관리콘솔에서 해당 SG ID 검색해서 직접 삭제 하면됨.
[ 마무리 ]
상당히 잘 짜여진 AWS EKS 업그레이드 워크샵 과정을 통해 짧은 시간 이지만, 업그레이드 전략에 따른 업그레이드를 경험해 볼 수 있는 시간이어서 유익했던 것 같다. 온프레미스 클러스터에 비해 'AWS 상에 구축된 EKS의 관리가 엄청나게 편리하구나' 라는 생각과 클러스터 업그레이드 이전 사전에 고려해야 할 사항들에 대해 꼼꼼히 챙겨야 할 부분이 상당히(?) 많다는 부담감은 여전히 사용자 몫으로 남는 것에 대해 조금은 불편함이 있다. 실무에서는 서비스 특성을 고려해야 하기 때문에 응용 실무팀 및 담당자와의 communication 과 사전 전략 검토에 많은 시간이 소요될 것으로 예상된다.
[ 참고 링크 모음 ]
- [AWS EKS BP] Best Practices for Cluster Upgrades* - Docs
- [EKS Blueprints for Terraform] Blue/Green Migration - Docs
- [AWS EKS Docs]
- [AWS Blog]
- [악분일상] EKS upgrade in-place방식에서 가장 걱정했던 것 - Blog
- [Jerry]
- [Devocean] EKS 버전 정책과 업그레이드 절차 살펴보기 - Blog
- [Blux] 무중단으로 EKS 클러스터 버전 업그레이드하기 - Blog
- [BBROS] Gitops를 활용한 AWS EKS Blue-Green 업데이트 적용기 - Blog
- [AWS Youtube]
'AEWS' 카테고리의 다른 글
| AEWS 11주차 - ML Infra(GPU) on EKS (0) | 2025.04.18 |
|---|---|
| AEWS 10주차 - K8s 시크릿 관리 Update (0) | 2025.04.10 |
| AEWS 8주차 - K8S CI/CD (0) | 2025.03.25 |
| AEWS 7주차 - EKS Mode/Nodes (Fargate, Auto-mode) (0) | 2025.03.17 |
| AEWS - 6주차 EKS Security (1) | 2025.03.11 |



